

開場:為什麼我後來幾乎每個研究都會走到 Profile Analysis
我是做教育研究的。這幾年回頭看自己做過的題目,從自我調節學習(self-regulated learning, SRL)、motivation,到 learner differences,雖然表面上研究主題不一樣,但有一件事越來越明確:很多研究計畫走到最後,我都會回到 Profile Analysis 這條思路。
這裡說的自我調節學習,指的是學生能不能自己設定目標、監控進度、調整策略,讓學習不只是被動完成,而是主動管理。
不是因為它比較新,也不是因為它看起來比較厲害。更根本的原因是:教育本質上是人的問題。
教育研究當然可以用很多變項來解釋。你可以看動機高低、策略使用、學習成績、背景變項,也可以做相關、迴歸、ANOVA、SEM。這些方法都重要,也都常用。但如果你真的在研究「人」,你很快就會發現:單一變項本身固然重要,可是真正更有意思的,往往是不同變項之間怎麼組合在同一個人身上。
有些學生不是單純動機高或低,而是動機高但策略弱;有些人策略很多,但監控能力差;有些人表面上總分差不多,可是背後其實是完全不同的 learner type。這些差異,如果只看平均效果,常常會被壓平。
這也是為什麼我後來越來越常用 Profile Analysis。它不是拿來炫技的統計方法,而是一條比較貼近教育問題本質的研究思路。這篇文章想談的,就是:為什麼有些研究做到最後,不能只停在平均數或單一變項關係,而必須進一步去看 profile。
Variable-centered 和 person-centered,問的根本不是同一件事
大部分研究生比較熟悉的,是 variable-centered 的分析方式。

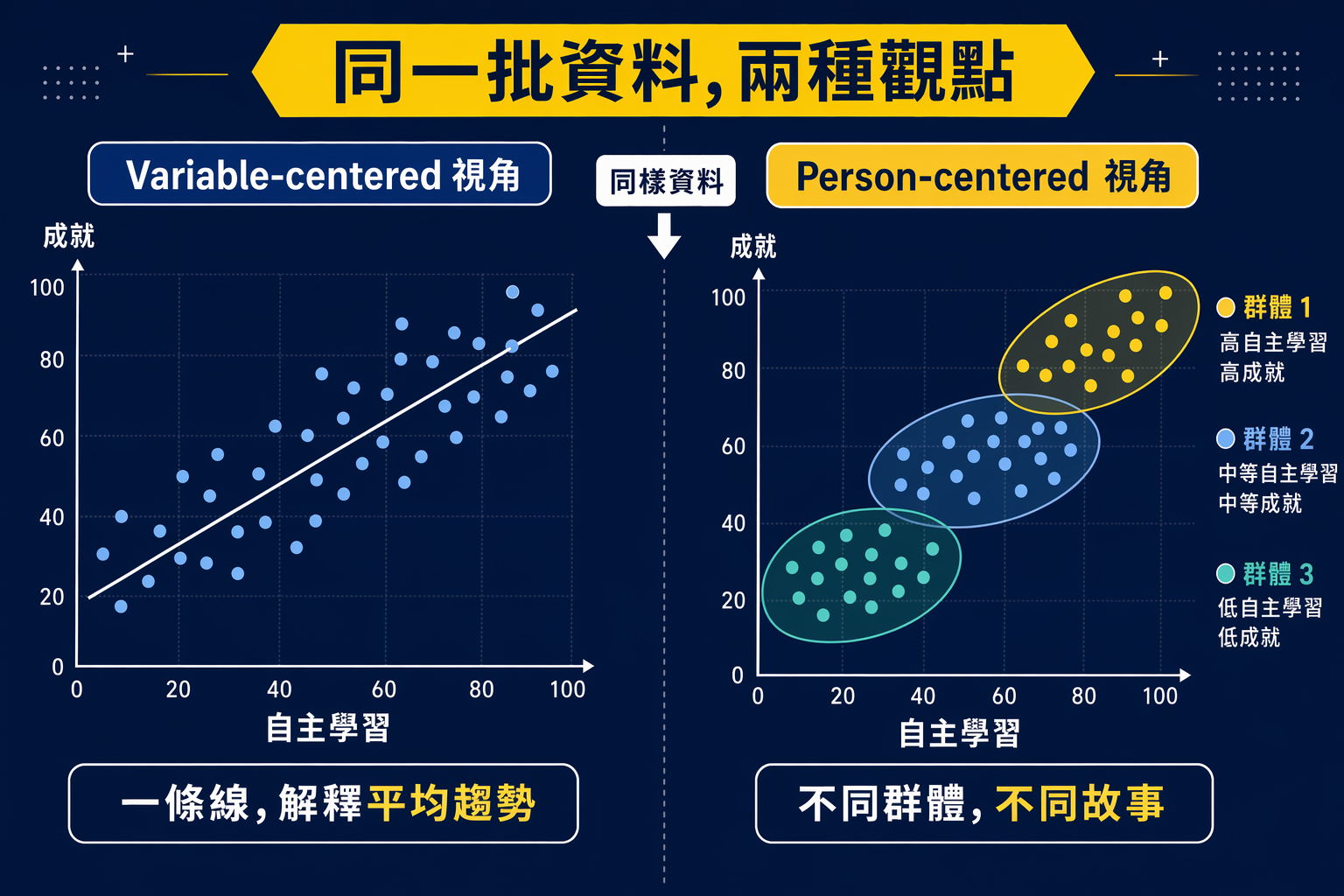
你問的是:
- X 和 Y 有沒有關係?
- 哪個變項可以預測哪個結果?
- 組別之間平均差多少?
這是迴歸、ANOVA、SEM 這一整條分析邏輯最擅長處理的問題。它很好用,也完全合理。很多研究問題,本來就應該這樣問。
但 person-centered 的出發點不一樣。
它問的是:
- 這群人裡面,是不是本來就有不同類型?
- 這些類型之間,各自有什麼特徵組合?
- 不同類型的人,後續表現、結果、風險或需求是否不同?
所以這不是「同一個問題的進階版」,而是另一種問問題的方式。
舉例來說,如果你研究學生的自我調節學習(SRL):
- variable-centered 可能會問:
「SRL 總分能不能預測成績?」
- person-centered 可能會問:
「學生是不是可以分成不同 SRL profile?而且不同 profile 的成績、動機、表現是否不同?」
這兩種做法都可以成立,但它們看到的東西不一樣。
為什麼教育研究特別需要這條思路
在很多教育研究裡,人不是平均數。
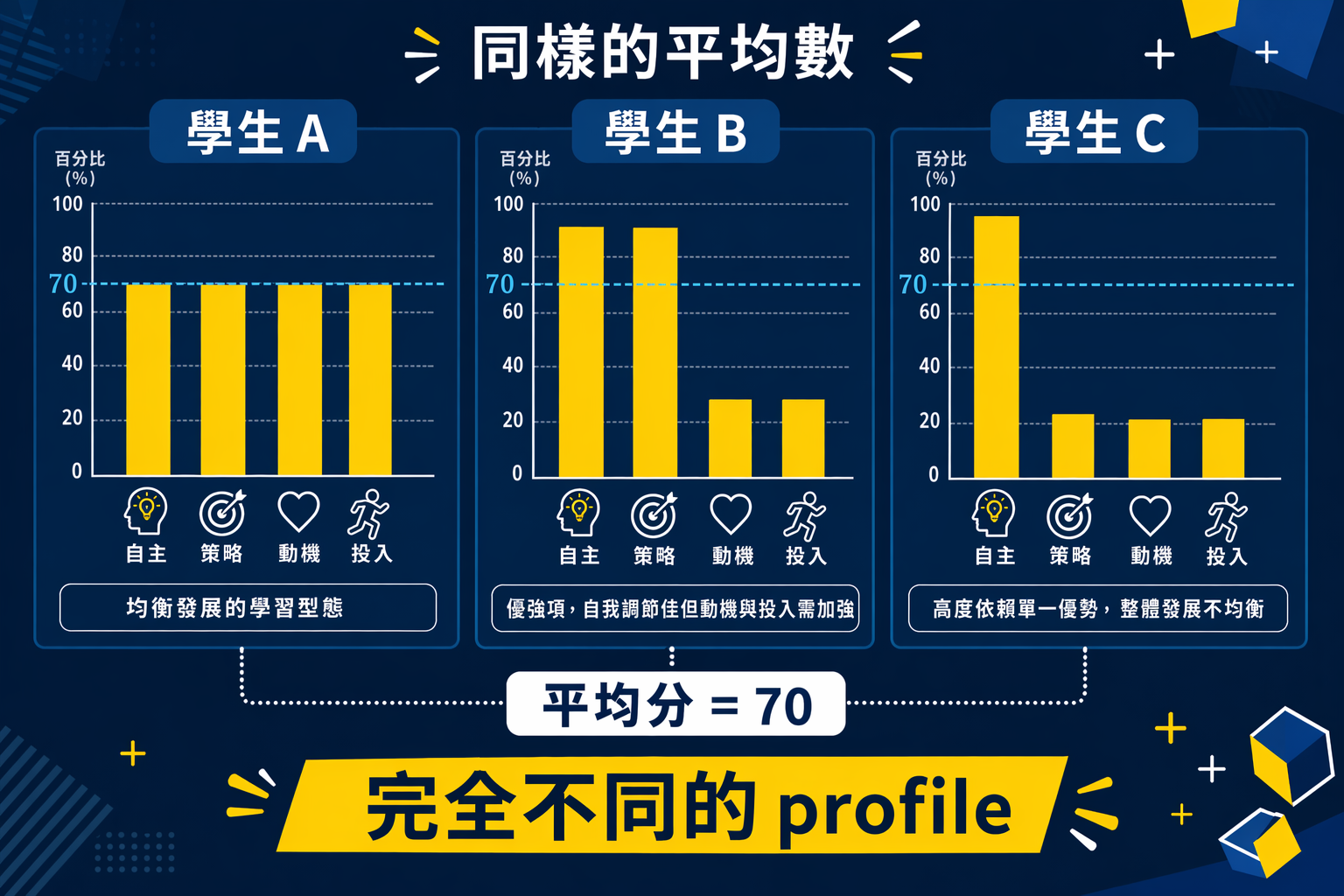
有些學生不是單純高或低,而是「某些面向很強、某些面向很弱」。你如果把這些人全部壓成一個總分,再拿去做相關或迴歸,分析本身可能沒有錯,但你可能已經把最有價值的教育訊息壓掉了。
例如,你研究大學生的時間管理策略,量表有四個分量表:計畫制定、優先排序、執行監控、彈性調整。你把四個分量表加總,然後發現總分和 GPA 相關 .28。
這個分析不是錯,而是不夠。
因為同樣一個總分下面,可能有完全不同的學生:
- 有些人計畫制定很強,但彈性調整很差
- 有些人每個面向都中等,但非常穩定
- 有些人執行監控很強,可是前期規劃很弱
這些人最後在學習表現上可能走向不同結果,但如果你只看一個總分,你就看不見這些差異。
這也是我認為 Profile Analysis 在教育研究裡特別有價值的原因。教育現場真正關心的,往往不是「平均來說這群學生怎麼樣」,而是:這群學生裡面,有哪些不同型態,而不同型態的人需要什麼樣的理解與介入。
Profile Analysis 到底在做什麼
先講最白話的一句:
Profile Analysis 想做的,不是看單一變項的效果,而是辨識人群裡不同的組合型態。
這裡有幾個概念要先分清楚:
1. Profile-based / person-centered
這是研究思路。
你相信樣本內部可能不是同質的,而是由不同類型的人組成。
2. Latent Profile Analysis(LPA)
這是最常見的統計方法之一。
它用多個連續指標去估計:樣本裡面可能存在幾個潛在類別,每個人屬於哪一類的機率有多高。
3. Cluster analysis
這也是分群方法,但原理和 LPA 不一樣。
cluster analysis 比較像距離導向;LPA 則是 model-based 的做法。
所以不要把這幾個東西完全畫上等號。
比較準的說法是:
- Profile Analysis 是一條 person-centered 的研究思路
- LPA 是實現這條思路的常見方法之一
- cluster analysis 是另一種可能做法
這篇文章比較關心的是前面那一層,也就是:你為什麼會需要這條思路。
典型的 Profile 會長什麼樣
這裡最容易被誤會,所以我要先講清楚:
不同研究裡浮現的 profile,不會長得完全一樣。
它會受很多因素影響:
- 你選了哪些指標
- 你的理論框架是什麼
- 樣本來自哪裡
- 你研究的是動機、策略、情緒,還是行為
所以 profile 的命名不是固定模板,也不是研究者愛怎麼命就怎麼命。比較合理的作法,是根據每個群組在不同指標上的相對高低,再給它一個有理論意義、但不過度誇張的描述。
在教育研究裡,常見的會像這幾種:
高策略組
- 多數關鍵指標都偏高
- 在部分研究裡,這類學生比較常和較佳學習結果一起出現
- 但不代表所有研究都一定如此
低策略組
- 多數指標都偏低
- 常見於較高風險或較低投入的群體
- 但依然要看研究脈絡,不能直接貼標籤
非均衡組
- 某些面向高,某些面向低
- 例如動機高但策略效率差
- 或認知策略強,但監控能力薄弱
這類組型往往最值得看。因為它們在 variable-centered 分析裡很容易被沖掉,但在教育介入上卻可能最重要。
辨識出 profile 之後,研究才真正開始
很多人以為分完 profile 就結束了,其實不是。
真正有意思的,通常是後面三件事。
第一,誰比較可能落在某個 profile?
例如:
- 性別
- 年級
- 自我效能
- 選課原因
- 動機型態
- 先備能力
這些背景變項,能不能預測某個人比較可能屬於哪一類?
這類分析常常能幫你回答:
某些 profile 是怎麼形成的。
第二,不同 profile 的結果有沒有差異?
例如:
- 哪一組成績比較好
- 哪一組留存率比較差
- 哪一組學習滿意度最低
- 哪一組最容易掉隊
這一步會讓 profile 從「描述」變成「有教育意義的分類」。
第三,不同 profile 需要不同介入嗎?
這是我自己覺得最有價值的地方。
如果某個介入對高策略組沒什麼用,但對低策略組很有效,那你對教學就有比較具體的建議。
這時候,研究就不只是統計上的分類,而是真的往精準介入走。
研究生最常誤會的幾件事
誤會一:只要把人分組,就叫 profile analysis
不是。
如果只是任意切高低分組,或者跑完 K-means 就直接說自己在做 profile analysis,方法上會太鬆。
這條線的重點,不只是「有分組」,而是這個分組能不能被理論支持、能不能被模型支持、能不能被合理解釋。
誤會二:指標隨便丟,跑出來就會有漂亮 profile
也不是。
你丟進模型的指標如果沒有理論基礎,最後跑出來的東西很可能只是統計切割,不是真正有意義的 learner types。
誤會三:profile 越多越厲害
這也不對。
有時候模型可以切出很多組,但如果某幾組樣本極少、難以解釋,或在教育上沒有實際區辨價值,那分再細也沒有意義。
誤會四:person-centered 一定比 variable-centered 高級
這個誤會很常見,但也最危險。
它不是比較高級,而是比較適合某些問題。
如果你的研究問題本來就是問「X 對 Y 的效果有多大」,那你硬做 profile 反而會把問題搞複雜。
什麼時候值得走這條思路
我通常會在這幾種情況考慮 profile-based analysis:
1. 理論上就懷疑樣本內部不是同一種人
例如 SRL、motivation、engagement、strategy use 這類構念,本來就很容易出現不同組合型態。
2. 平均效果看起來不大,但你直覺覺得不是沒有東西
有時候 effect size 很小,不是因為沒有作用,而是因為不同 subgroup 的方向或強度不同,被平均結果壓掉了。
3. 你的研究目的不是描述平均趨勢,而是找出不同 learner types
如果你的目標是辨識風險群、高潛力群,或不同介入需求,這條線通常更有意義。
4. 你真的想回答「哪種學生適合哪種做法」
這種問題,person-centered 常常比單純的平均效果更接近教育現場。
什麼時候不要硬用
也要反過來講,免得把這條方法神化了。
1. 你的研究問題其實很單純
如果你要問的只是某個變項是否預測某個結果,variable-centered 通常就夠。
2. 樣本太小
這種分析通常比一般回歸或 ANOVA 更吃樣本。
到底要多少,不能硬講一條線,因為會受模型複雜度、指標品質、class separation 等因素影響。
但如果你的樣本本來就偏小,又沒有強理論支撐,我通常不會建議你硬做。
3. 你只是因為它聽起來比較厲害
這個理由最不該用。
方法不是拿來裝飾研究的,方法是拿來回答問題的。
如果你的問題本來不需要它,硬套只會讓整篇研究變得不穩。
結語:這不是比較高級,而是比較貼近某些教育問題
我後來會一直用 Profile Analysis 這條思路,不是因為它比較時髦,而是因為它幫我看見了另一層研究問題。
不是每個研究都該做 profile-based analysis。
但有些研究,如果你只看平均效果,你真的會錯過最重要的那群人。
這也是為什麼我會說,這條方法思路的價值,不在於它能不能幫你跑出幾個類別,而在於它能不能讓你對「人」的理解更接近真實。
當你開始問的不只是「平均來說有沒有差」,而是「這群人裡面有哪些不同型態,而這些型態分別意味著什麼」,你才真正走進了 person-centered 的世界。
延伸閱讀
前後測與方法選擇
- 📖 如何分析前、後測:進步分數 — 前後測分析的起點,對照 person-centered 看 profile 的思路
- 📖 前後測統計方法選擇:常態假設怎麼看? — 方法選擇前該問的第一個前提
多變項與進階建模
- 📖 SEM 實作路線圖/入口橋樑文 — 當你想進到更結構化的多變項建模時的路徑圖
- 📖 好書推薦:Multivariate data analysis — MANOVA / profile-based 方法的教科書起點