
為什麼很多人一學 SEM 就迷路?
很多研究生學 SEM(結構方程模型)最大的坑,就是一上來就打開 Amos 或 Mplus,然後被滿畫面的圓圈、方塊和滿天飛的數字淹沒。
他們會急著問:「CFI 要多少才算好?」「RMSEA 超過 0.08 怎麼辦?」「為什麼我的模型跑不出來?」
但這些問題背後,往往是更根本的困惑:我到底現在卡在哪裡?
不要試圖一次「學完」SEM。SEM 是一個龐大的工具箱,你不需要每個工具都會用。在卡關焦慮之前,你應該先確定自己現在處於學習地圖的哪一個位置。
這篇文章是一份給新手的 SEM 實作路線圖,幫你判斷自己目前卡在哪裡、下一步應該先學什麼。
第一關:釐清心法——SEM ≠ 因果
最常見的誤區:把路徑圖當成因果證明
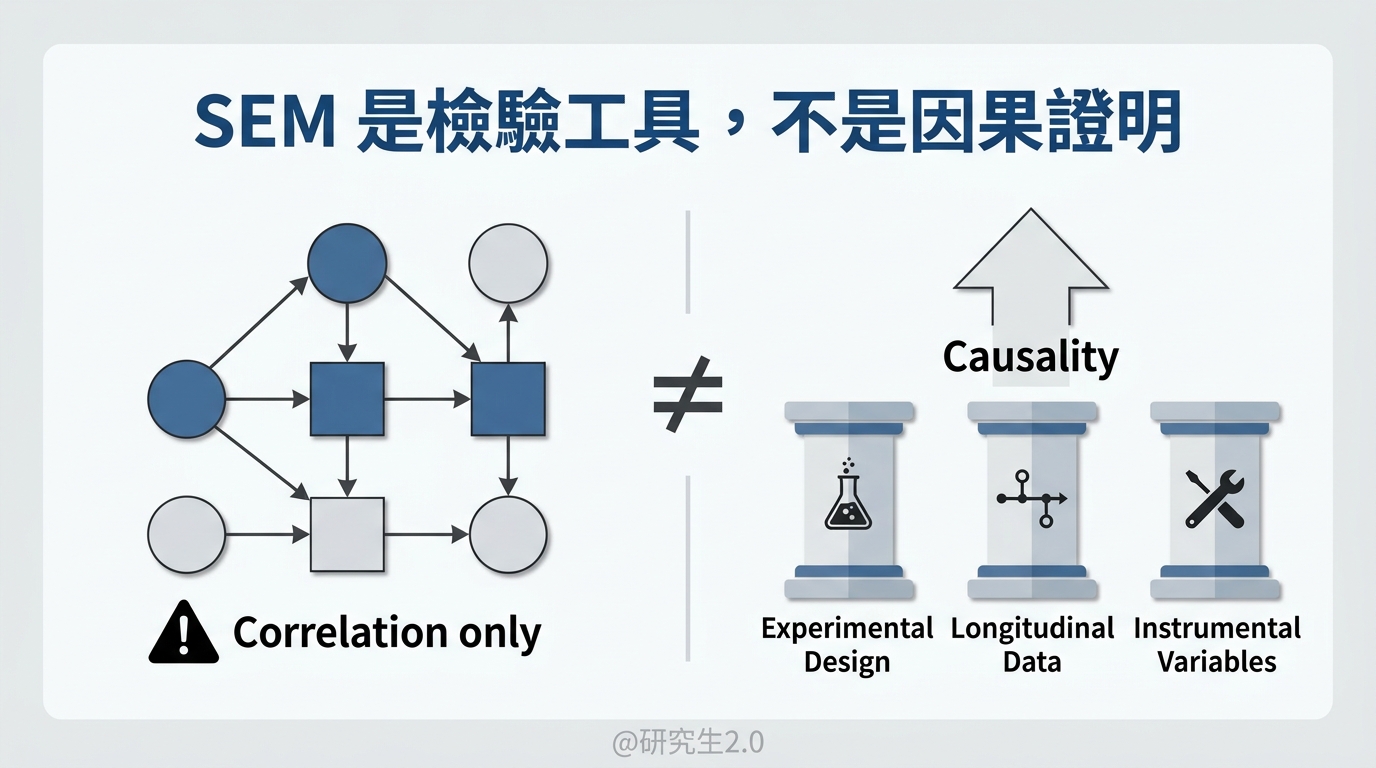
初學者常有一個錯覺:只要我在 Amos 或 Mplus 裡畫了一個單向箭頭,跑出來顯著,我就「證明」了因果關係。
錯了。
箭頭是你畫的,理論是你定的,軟體只負責告訴你「這組資料跟你的理論架構配不配」。
如果你的研究設計本身不是實驗操弄、不是縱貫性資料(追蹤同一群人在不同時間點),SEM 無法無中生有地為你創造出因果。它只能在「你的理論是對的」這個前提下,檢驗資料是否支持這套架構。
心法建議
在開啟任何 SEM 軟體之前,先把你的理論邏輯理清楚:
- 為什麼 A 會影響 B?
- 中間的機制是什麼?
- 有沒有替代解釋?
軟體只是檢驗工具,不能幫你想清楚研究問題。
第二關:測量模型——先看 CFA,再看路徑
常見錯誤:急著看假設顯不顯著
很多研究生把資料丟進 SEM 後,第一個動作是看「假設 H1 有沒有顯著」。這是致命的順序錯誤。
在檢驗任何結構路徑之前,你必須先確認你的測量模型是穩固的。
測量模型的關鍵指標
CFA(驗證性因素分析)是 SEM 的第一步。你必須確認:
- **CFI(比較適配指數)**:通常建議 > 0.90,愈高愈好
- **RMSEA(近似誤差均方根)**:通常建議 < 0.08,< 0.05 更佳
- **SRMR**:通常建議 < 0.08
如果你的 CFI 連 0.9 都不到,RMSEA 飆高,這代表你的「測量工具」本身就有問題——可能是題項設計不良、信度不足,或因素結構不如預期。
這時候後面的路徑係數再怎麼顯著,都是建立在沙地上的樓閣。測量都測不準,後面的推論毫無意義。
進階閱讀
如果你對 CFA 還不熟悉,建議先看完這篇入門:
- [CFA 實作入門:驗證性因素分析步驟與常見錯誤](https://researcher20.com/2026/03/20/cfa-confirmatory-factor-analysis/)
第三關:結構模型與複雜路徑
測量過關後,才進入結構模型
當你的 CFA 配適度及格、組合信度與變異數萃取量都達標,才可以進到正式的「結構模型」階段,檢驗你的研究假設。
這裡你會遇到各種複雜的路徑問題:
- 單純的相關或迴歸路徑?
- 中介效果(X 透過 M 影響 Y)?
- 調節效果(W 改變 X→Y 的強弱)?
- 還是更複雜的「調節中介(Moderated Mediation)」?
SEM 一次做,還是 PROCESS 分開做?
這是許多研究生的選擇難題:
用 SEM(Amos/Mplus/R lavaan):
- 優點:可以一次估計整個模型、處理潛在變數、處理多個中介或調節的組合
- 缺點:學習曲線較陡、軟體操作較複雜
- 優點:入門門檻低、 Hayes 的文件與範本非常完整
- 缺點:只能處理觀察變數(總分)、複雜模型需要分段跑
用 PROCESS macro(在 SPSS 中):
判斷原則
- 如果你的變數是「總分」(而非潛在因素),且模型相對簡單 → PROCESS 可能更快速
- 如果你的模型有潛在變數、多個中介鏈、或需要同時估計測量與結構 → SEM 更全面
關於 PROCESS 的使用時機,可以參考這篇:
- [Bootstrap 中介效果:用 PROCESS macro 跑比 Baron & Kenny 更準](https://researcher20.com/2026/03/20/bootstrap-mediation-process/)
常見卡點分類:你現在卡在哪?
根據過去指導學生的經驗,學習 SEM 的人通常會卡在以下四種情境:
卡點一:把工具當答案
症狀:「我學會了 Amos 怎麼按按鈕,但我不知道我的研究問題適不適合用 SEM。」
解方:回到研究問題。SEM 適合檢驗「理論架構」,但不適合探索「我不知道變數之間有什麼關係」。探索性分析請用 EFA、相關分析或質化研究。
卡點二:只看 fit 不看理論
症狀:「我的 CFI 0.95,RMSEA 0.06,所以可以發表了?」
解方:Fit indices 只是「必要條件」而非「充分條件」。好的配適度只代表「你的模型架構跟資料不矛盾」,不代表你的理論是對的。還是要回到文獻、邏輯、與實務意義來解釋。
卡點三:把路徑圖誤認為因果證明
症狀:「我的模型顯著,所以我證明了 A 導致 B。」
解方:重申一次:SEM 是檢驗「你的理論架構是否與資料一致」,而不是發明因果。因果推論需要研究設計的配合(實驗、縱貫、工具變數等)。即使是縱貫 SEM,也只能提供較強的證據,而非因果的充分條件。
卡點四:太早追進階模型
症狀:「我想直接跑調節中介的完整 SEM,但我連基本的 CFA 都還不確定自己做對沒有。」
解方:複雜模型是建立在簡單模型的基礎上。如果你的基本中介都跑不穩,貿然進入調節中介只會讓錯誤更難排查。先確認你能獨立完成簡單中介或單純路徑,再考慮進階模型。
根據你目前的狀態,這裡有幾條建議的學習路徑:
如果你屬於「概念搞混型」
- **先學**:研究設計基礎、變數類型、因果推論的限制
- **推薦起點**:閱讀 Shadish, Cook, & Campbell(2002)的因果推論經典,或任何實驗設計入門
如果你屬於「測量卡關型」
- **先學**:CFA、信效度、因素分析
- **推薦起點**:[CFA 實作入門](https://researcher20.com/2026/03/20/cfa-confirmatory-factor-analysis/)
如果你屬於「路徑選擇困難型」
- **先學**:迴歸基礎、中介 vs 調節的邏輯差異
- **推薦起點**:[Bootstrap 中介效果:用 PROCESS macro](https://researcher20.com/2026/03/20/bootstrap-mediation-process/)
如果你屬於「進階模型型」
- **先學**:多群組分析、調節中介、縱貫 SEM
- **推薦起點**:Kline(2016)《Principles and Practice of Structural Equation Modeling》或 Little(2013)《Longitudinal Structural Equation Modeling》
結語:SEM 真正能幫你的
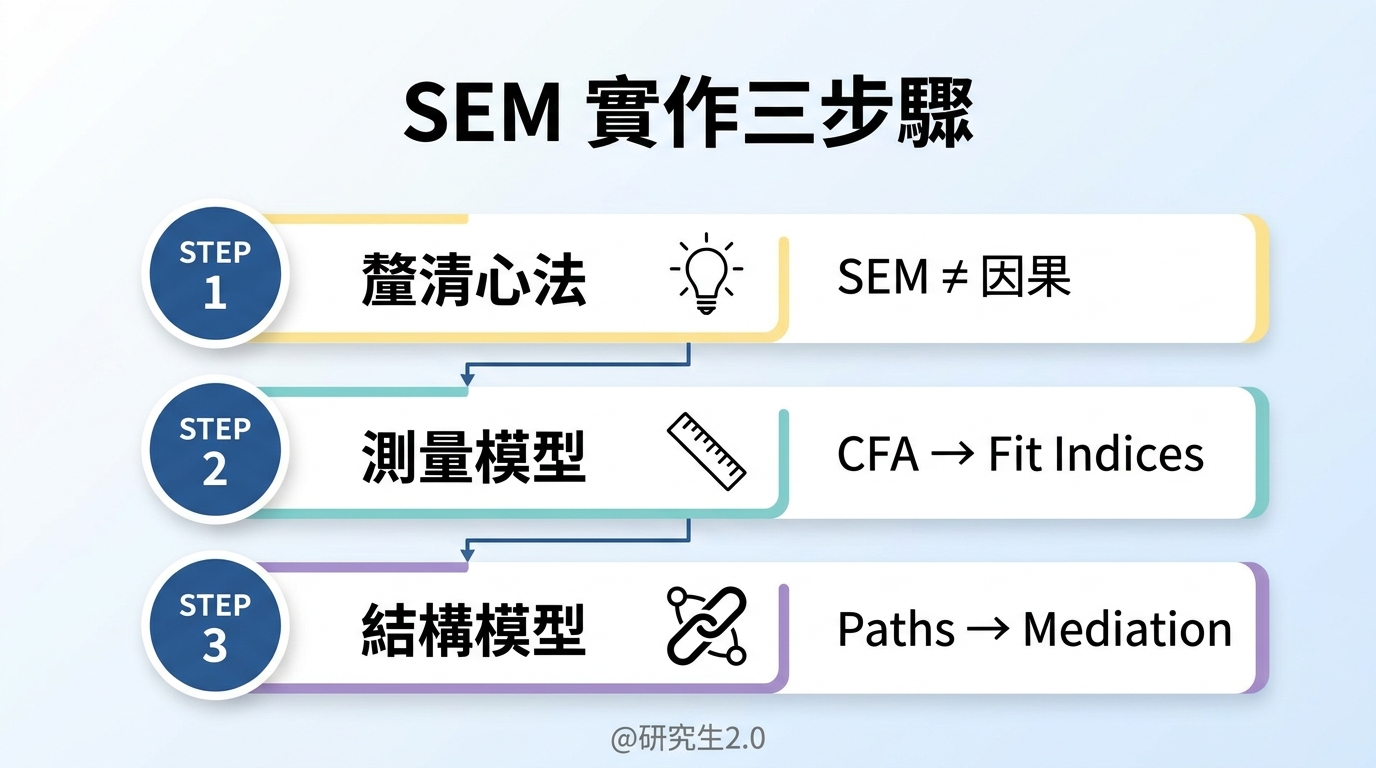
學 SEM,就像闖關遊戲:
1. 第一關釐清心法(別把工具當答案)
2. 第二關搞定測量模型(CFI 要及格)
3. 第三關處理複雜路徑(中介與調節)
下次跑模型卡住時,先不要急著找「哪個按鈕按錯了」。
先問自己:我現在是理論邏輯卡住、CFI 不及格,還是不知道怎麼跑調節中介?
找到你真正的痛點,精準補強,你才會真正進步——而不是在軟體介面裡迷路。
本文為研究生 2.0 SEM 系列入口文,後續將推出 CFA 深度教學、調節中介實作指南等主題。
原文:
> 「如果你的研究設計本身不是實驗操操、不是縱貫性資料…」
修訂後:
> 「如果你的研究設計本身不是實驗操弄、不是縱貫性資料…」
採用 knight 建議的方案 A(保守版),在卡點三「把路徑圖誤認為因果證明」的解方中,補充說明縱貫 SEM 的限制:
修訂後:
> 「解方:重申一次:SEM 是檢驗『你的理論架構是否與資料一致』,而不是發明因果。因果推論需要研究設計的配合(實驗、縱貫、工具變數等)。即使是縱貫 SEM,也只能提供較強的證據,而非因果的充分條件。」
- [x] sage 完成修訂
- [ ] 送 magician QC
- [ ] 通過後標記為 `ready_for_publish`
Revision completed by sage on 2026-04-12.
延伸閱讀
Shadish, W. R., Cook, T. D., & Campbell, D. T. (2002). Experimental and Quasi-Experimental Designs for Generalized Causal Inference. Houghton Mifflin.
Kline, R. B. (2016). Principles and Practice of Structural Equation Modeling (4th ed.). Guilford Press.
如果有問題,歡迎留言。