作因素分析時,常會碰到兩個讓人頭痛的名詞:因素負荷量 (factor loadings) 與特徵值 (eigenvalues)。加上 scree plot 的判斷,很多人在這幾個步驟都卡住了。這篇的目標很簡單:不講太多數學,把這幾個概念說清楚,以及它們實際上在回答什麼問題。
特徵值 (Eigenvalues):這個因素值不值得留?
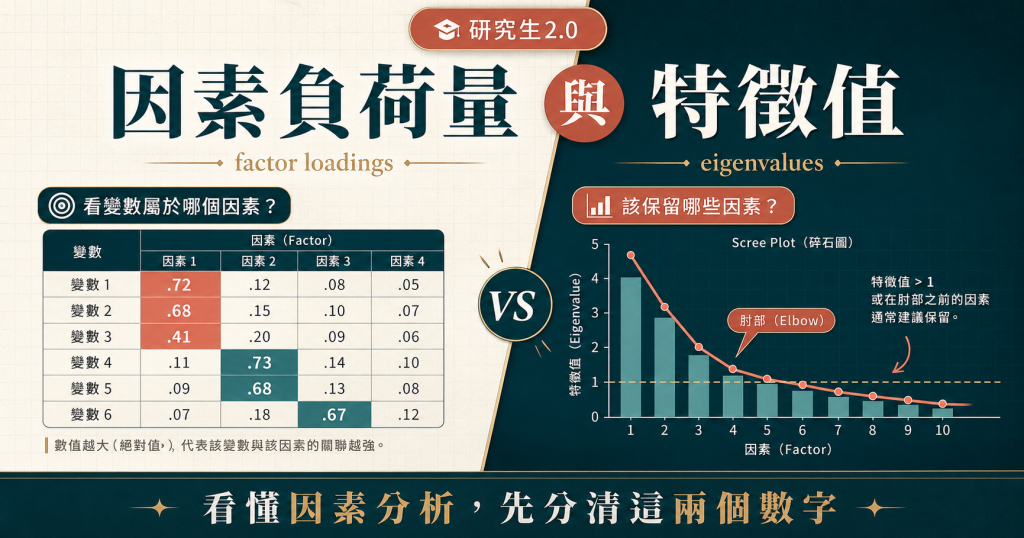
特徵值(有時也稱為 characteristic roots)回答的是一個問題:這個因素能代表多少個變數的資訊?
以 10 個變數為例,所有因素的特徵值加總等於 10。如果某個因素的特徵值是 0.5,代表它只解釋了半個變數的資訊量——留下這個因素,對精簡變數結構的幫助非常有限。
常見的判斷準則(rule of thumb)是:特徵值 < 1 的因素通常可以刪除(Harman, 1976)。背後的邏輯是,若特徵值小於 1,代表這個因素解釋的資訊量連一個原始變數都不如,自然沒有保留的必要。這個標準在 EFA(探索性因素分析)初步判斷時最常使用,大部分期刊也接受。不過它並非最嚴謹的方式,最好搭配下面的 scree plot 和理論意義一起判斷。
除了看特徵值,也可以觀察每個因素解釋的 % of variance,了解所有因素加總能解釋多少總變異量。
Scree Plot:到底該留幾個因素?
Scree Plot 是另一個判斷因素數量的工具。它把每個因素的特徵值由高到低畫成折線圖,你要找的是線條突然變平的轉折點——轉折點之前的因素留下,之後的捨棄。
轉折點後,每多留一個因素,能新增的解釋量已經非常有限,留下來只會讓模型變複雜,不會更清楚。
需要注意的是,Scree Plot 有一定的主觀性。如果折線是慢慢變平而非突然斷下去,不同人看到的轉折點可能不一樣。這時候不要硬選,應回頭對照理論:這份量表在概念上應該測幾個維度?特徵值準則、scree plot 和理論意義三者一起看,是最穩的做法。
因素負荷量 (Factor Loadings):這個因素代表什麼?
確定保留幾個因素之後,下一步是理解每個因素的意義——靠的就是因素負荷量。
因素負荷量是個別變數與因素之間的相關程度(未轉軸前),數值介於 -1 到 1 之間,類似 Pearson 相關係數。因素負荷量的平方,就是該因素能解釋這個變數多少的 variance。例如負荷量為 0.4,代表能解釋 16% 的變異量。
依照 Hair et al. (1992) 的說法,低於 0.4 的因素負荷量偏低,0.6 以上算高。命名因素的方式,就是找這個因素下負荷量最高的幾個變數,看它們的共同主題——那就是因素的名字。
要特別注意的是 cross-loading:如果同一個變數在兩個因素的負荷量都偏高,代表這個變數的概念跨了兩個維度,不夠「乾淨」。遇到這種情況,應考慮刪題或重新檢視題項設計。
最後提醒:決定一個變數是否歸入某個因素,取決於理論而非純粹數字,數據只是佐證。有時候因為樣本或其他因素,結果稍微不如預期也是可以接受的。
參考文獻
Hair, J. F., Black, B., Babin, B., Anderson, R. E., & Tatham, R. L. (1992). Multivariate Data Analysis (6th ed.). New York: Macmillan.
Harman, H. H. (1976). Modern factor analysis. Chicago: University Of Chicago Press.
Kim, J., & Mueller, C. W. (1978). Introduction to factor analysis: What it is and how to do it. Newbury Park, CA: Sage.
您好~~
有個小問題
想要請問一下特徵值可以設為大於1以上嗎??
那麼又該如何去解釋要設定大於1呢??
tks~~