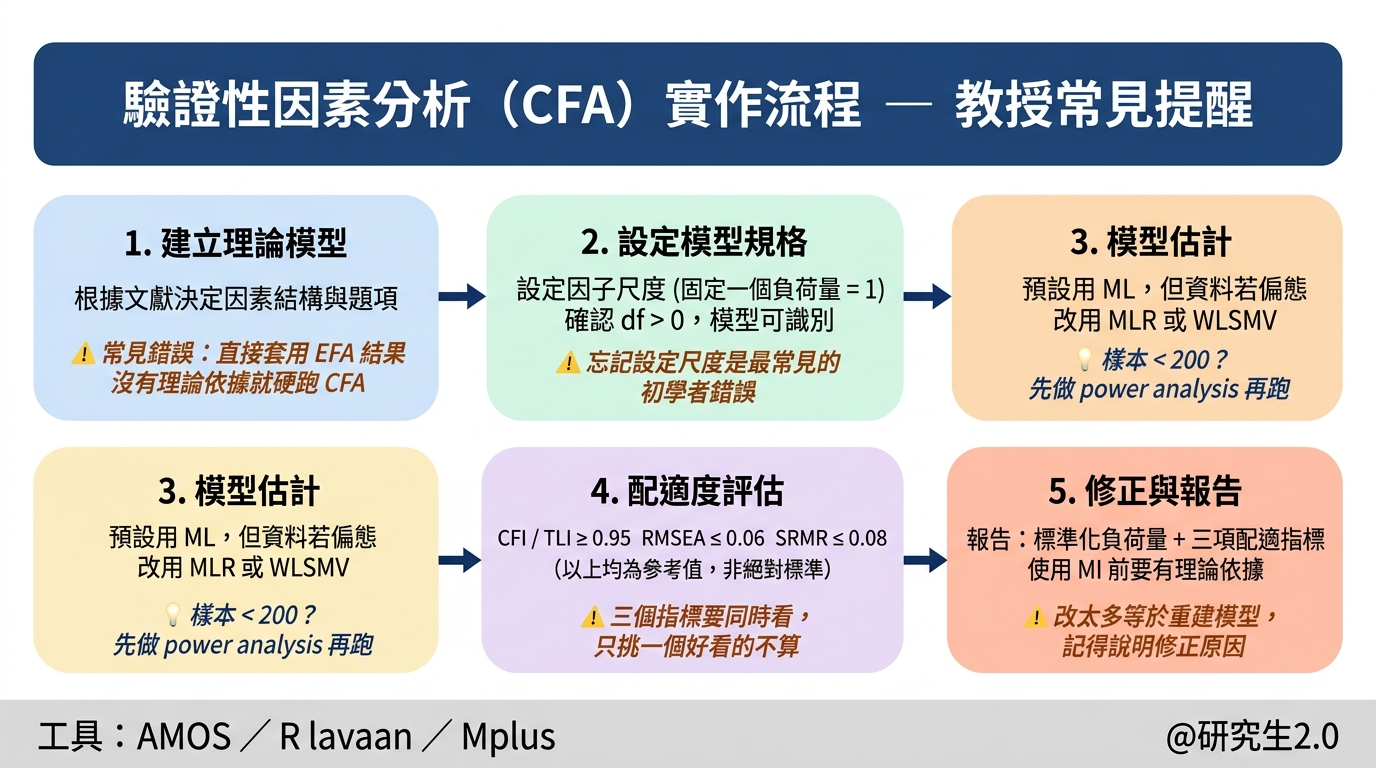
缺失值怎麼處理?從 MCAR、MAR 到多重插補,一篇說清楚
學生交來初稿,我翻到方法段,看到一句話:「本研究刪除含有遺漏值的樣本,最終有效樣本為 N = 218。」
我問:「原始問卷收了多少份?」
他說:「251 份。」
我說:「你刪掉了 33 個人,占將近 13%。你有沒有想過,這 33 個人為什麼沒有填完?」
他沉默了一下。這個問題,很多學生沒有想過。
缺失值不是「髒資料」,是資訊
缺失值(missing data)在量化研究裡幾乎無可避免。問卷有人跳題、有人漏填、有人中途離開;追蹤研究有人失聯。問題不是「資料有缺失就不好」,而是:這些缺失是怎麼產生的?
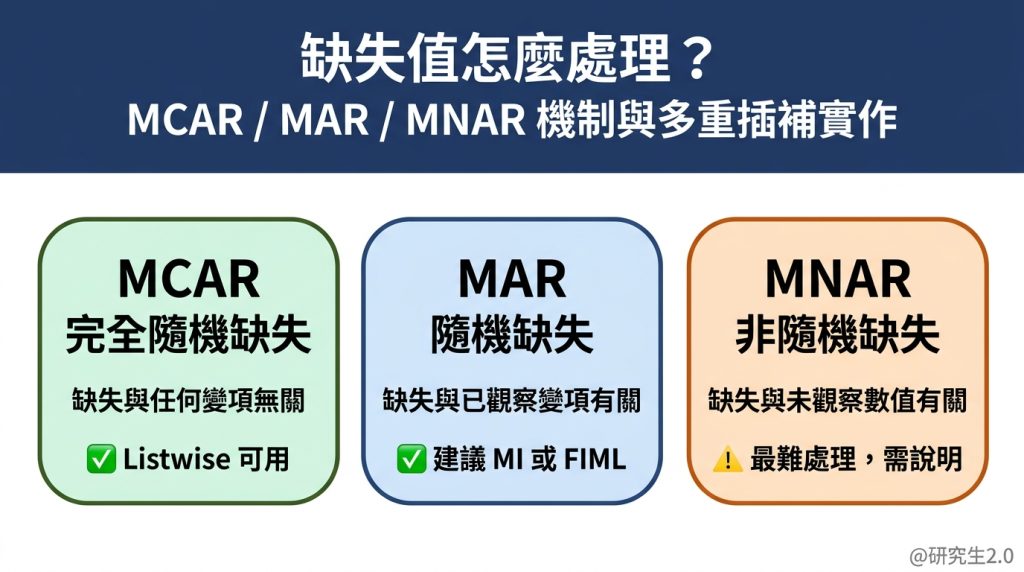
Rubin(1976)把缺失值的機制分成三類,這個分類直接決定你應該用什麼方法處理:
-
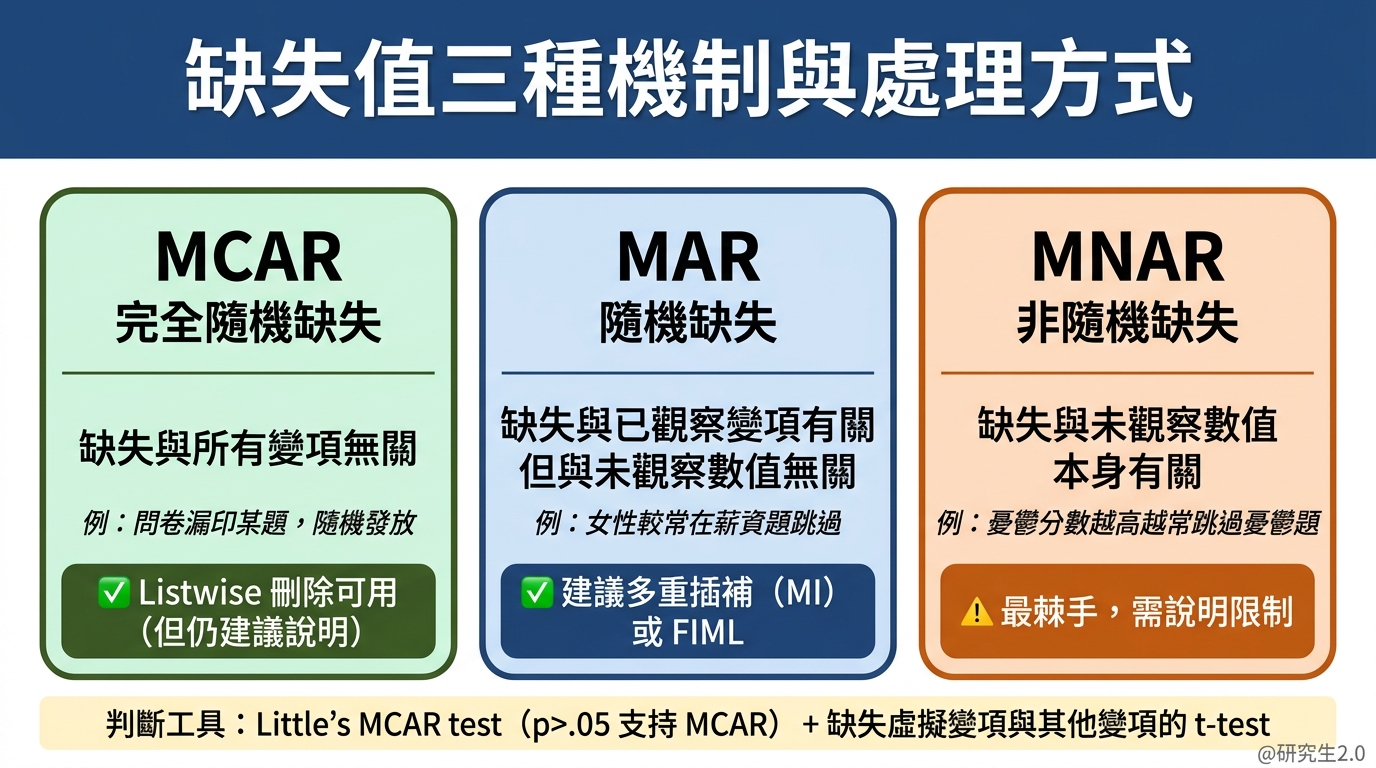
MCAR(Missing Completely At Random,完全隨機缺失)
缺失與任何變項的值完全無關。例如:問卷印刷有個版本漏印了一題,哪些人拿到這份問卷是隨機的。
這是最理想的情況,但現實中很少見。 -
MAR(Missing At Random,隨機缺失)
缺失與其他已觀察到的變項有關,但與遺漏的數值本身無關。例如:女性比男性更容易在薪資題跳過,但控制性別後,缺失就不再系統性地和薪資高低有關。
這是最常見的假設,多重插補和 FIML 都以 MAR 為前提。 -
MNAR(Missing Not At Random,非隨機缺失)
缺失和遺漏的數值本身有關。例如:憂鬱分數越高的人越可能跳過憂鬱相關題項。
這是最棘手的情況,標準統計方法無法完全解決,需要特殊模型或明確說明限制。
Listwise Deletion 的問題
Listwise deletion(刪除含有缺失值的整筆資料)是最常用的做法,SPSS 的預設值也是這個。它只在 MCAR 的情況下不會造成偏誤——因為只有在缺失完全隨機時,刪掉這些人才不會讓留下來的樣本變得「特別」。
如果缺失是 MAR 或 MNAR,listwise deletion 會:
- 造成樣本偏誤:留下來的樣本不再能代表原始母群
- 損失統計力:樣本數減少,估計誤差增大
- 低估標準誤:某些情況下讓結果看起來比實際更顯著
⚠️ 容易犯錯的地方:學生在方法段只寫「刪除含有遺漏值的樣本」,但沒有說明缺失率、沒有檢驗缺失機制、也沒有討論這個做法對結論可能的影響。審稿人看到這裡,會直接問:你怎麼知道缺失是 MCAR?
現代處理方式:MI 和 FIML
當前方法學文獻推薦的兩種主流做法是多重插補(Multiple Imputation, MI)和完整資訊最大概似法(Full Information Maximum Likelihood, FIML)。兩者都在 MAR 假設下比 listwise deletion 表現更好。
多重插補(MI)
核心邏輯:不是用一個值去填補缺失,而是建立多個完整資料集(常見做法是 20 次以上,缺失比例較高時可增加插補次數),每次填補都反映填補的不確定性,最後合併分析結果。
操作工具:SPSS(Analyze → Multiple Imputation)、R mice 套件、Stata mi impute。
適合情況:缺失值分散在多個變項;想用不同軟體分開做插補和分析。
完整資訊最大概似法(FIML)
在 SEM 或 CFA 模型中,FIML 讓模型在估計時直接使用每個受試者提供的所有有效資訊,不需要預先填補缺失值。FIML 通常適用於以模型為基礎的分析(如 CFA、SEM、路徑分析),不是所有統計程序都能直接套用。
操作工具:AMOS(預設支援)、R lavaan(missing = "fiml")、Mplus(DATA: LISTWISE = OFF)。
適合情況:跑 CFA 或 SEM,缺失值主要在觀察變項上。
⚠️ 容易犯錯的地方(一):學生以為 FIML「自動處理了缺失值所以不用報告」。其實 FIML 也需要在方法段說明:使用 FIML 估計,假設缺失機制為 MAR。
⚠️ 容易犯錯的地方(二):用 MI 時,插補模型包含的變項不夠完整。MI 的插補品質取決於插補模型有多少有效預測變項——把所有分析相關變項都納入插補模型,結果才可靠。
怎麼檢驗缺失機制?
在方法段說明缺失值處理之前,應該先報告你如何判斷缺失機制。
Little’s MCAR test:SPSS 有內建(Analyze → Missing Value Analysis → Little’s MCAR test)。若 p > .05,表示沒有足夠證據拒絕 MCAR 假設,常被視為與 MCAR 相容——但這不等於「確認是 MCAR」,統計檢驗只能提供線索,機制判斷仍需結合理論與資料情境。
輔助變項分析:建立「是否缺失」的虛擬變項,與其他變項做 t-test 或卡方檢定。如果缺失組和完整組在某些變項上有顯著差異,就有理由懷疑不是 MCAR。
⚠️ 容易犯錯的地方:MNAR 無法用標準統計方法驗證(因為你沒有缺失的數值)。遇到可能是 MNAR 的情況,誠實在討論段說明是更合適的做法,而不是假裝問題不存在。
如何在論文裡報告?
缺失值的報告應包含:
- 缺失率:整體缺失率(如:缺失佔全部資料格的 X%);各關鍵變項的缺失情況
- 缺失機制:如何判斷(Little’s MCAR test 結果,或輔助分析結論)
- 處理方式:用了哪種方法(MI / FIML / listwise)以及選擇理由
- MI 的細節(若使用):插補次數、插補模型包含哪些變項、軟體
範例寫法:「本研究資料缺失率為 4.3%,各變項缺失率均低於 10%。Little’s MCAR test 結果不顯著(χ² = 12.3, df = 14, p = .58),初步支持缺失隨機假設。採用多重插補法(R mice 套件,M = 20 次),插補模型包含所有分析變項。」
缺失率多高就不能用?
沒有絕對的門檻。常見的粗略參考是:
- 5% 以下:通常影響不大,listwise 或 MI 均可,但應說明。
- 5%–20%:建議用 MI 或 FIML,並報告缺失機制檢驗。
- 20% 以上:需要非常謹慎,MI 仍可嘗試,但解釋要保守,且需討論對結論的潛在影響。
這些只是經驗參考,不是硬性標準。更重要的判斷仍是:缺失是否系統性地影響估計結果? 也需要交代缺失集中在哪些變項——是 outcome 缺失多?還是某個背景變項?是否集中在特定群體? 5% 的 MNAR 可能比 15% 的 MCAR 更嚴重。
如果有問題,歡迎留言。
更新記錄:2026-03 首次發布。…
缺失值怎麼處理?從 MCAR、MAR 到多重插補,一篇說清楚 Read More »