「老師,我的 conceptual framework 有一個 mediator 和一個 moderator……」
我問:「你知道兩個的差別嗎?」
他想了很久:「都是在影響變數之間的關係?」
對了一半。但如果寫進論文,這個「一半」會讓方法段整個站不住腳。
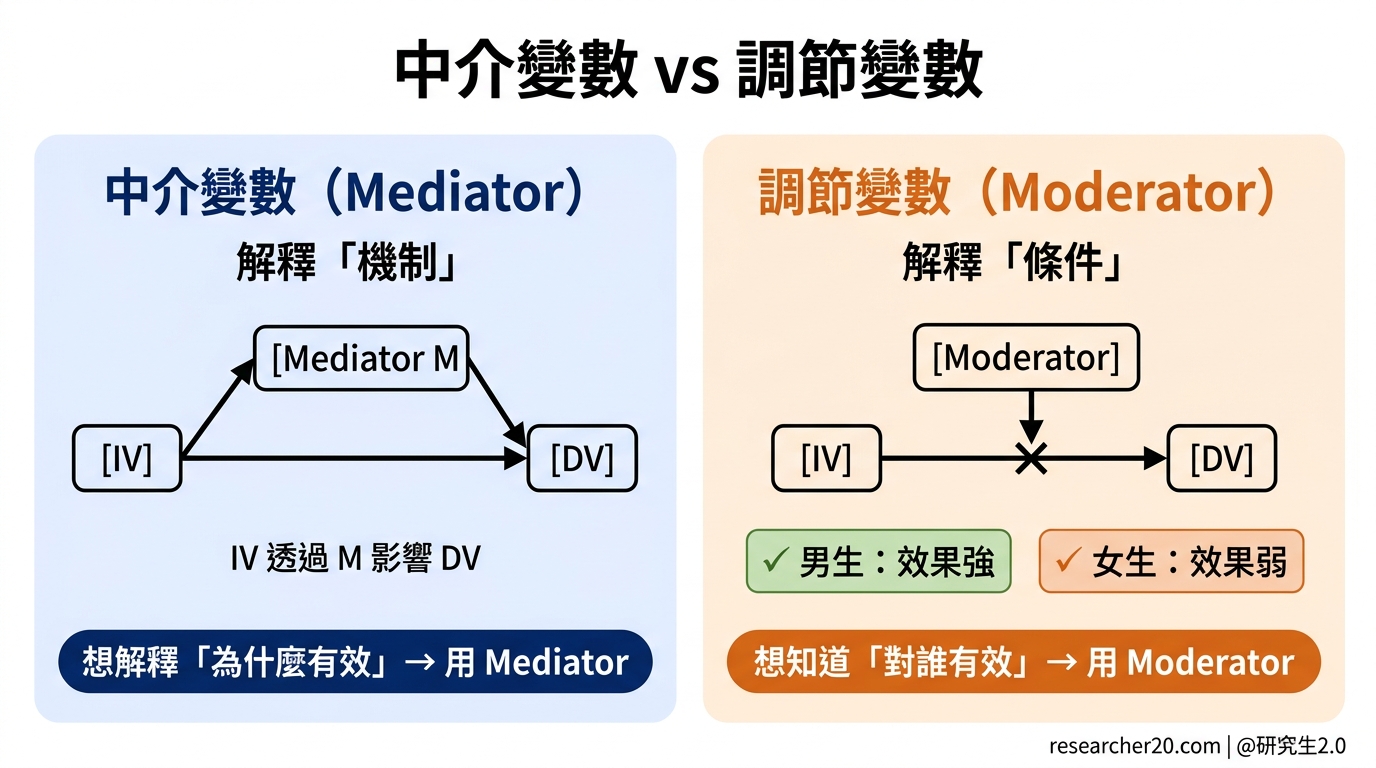
中介變數(Mediator):解釋「機制」
Mediator 回答的問題是:IV 為什麼能影響 DV?透過什麼路徑?
舉個例子:
使用 AI 寫作工具(IV)→ 降低認知負荷(Mediator)→ 提升寫作表現(DV)
「降低認知負荷」就是 mediator——它說明了 AI 工具如何影響學習的過程,是 IV 到 DV 的中間橋梁。
簡單說:Mediator 解釋機制,回答「怎麼來的」。
測試 Mediation 的步驟(Baron & Kenny, 1986)
要確認 mediation 是否存在,需要依序確認四個條件:
IV → DV 有顯著關係(沒有這個,mediator 就沒意義)
IV → Mediator 有顯著關係
Mediator → DV 有顯著關係(控制 IV 之後)
放入 mediator 後,IV → DV 的係數減小(完全 mediation:降為不顯著;部分 mediation:係數仍顯著但變小)
⚠️ 現代研究多用 Bootstrap 法(如 PROCESS macro) 取代 Baron & Kenny 步驟,更直接測試間接效果(indirect effect)的信賴區間。
調節變數(Moderator):解釋「條件」
Moderator 回答的問題是:IV 對 DV 的影響,在什麼情況下更強?更弱?對誰有效?
舉個例子:
AI 工具對寫作表現的影響(IV → DV),是否因學生的先備知識高低而不同?
「先備知識」就是 moderator——它不解釋機制,而是說明這個效果的邊界條件 。
如果你熟悉 ANOVA,moderator 其實就是交互作用(interaction)。
簡單說:Moderator 解釋條件,回答「對誰、在什麼情況下有效」。
一句話分辨兩者
Mediator = IV 透過什麼影響 DV(機制)
你的研究問題就決定了你要用哪個:
想解釋「為什麼有效」→ mediator
想知道「對誰有效、什麼情況下有效」→ moderator
怎麼選:Baron & Kenny (1986) 的建議
這篇被引用超過 40,000 次的論文提供了一個務實的判斷原則:
如果 IV 與 DV 之間的關係很穩定、很強 → 用 mediation 解釋它怎麼發生的
如果 IV 與 DV 之間的關係不一致、有時強有時弱 → 先看 moderation,找出邊界條件
💡 如果兩者都想研究,就是 moderated mediation 或 mediated moderation ,進階但也更完整。
延伸閱讀
Baron, R.…