
Stata: 切割字串
今天拿到一個要分析的問卷,不看不知道,一看快昏倒,裡面有一題問卷的回答像下面一樣:
變數裡面全部是 string,這也就算了。一個 string 裡面包含了五個問題,每個問題有五個選項,這還讓不讓人活啊?這樣是沒辦法跑任何分析的,得先將五個問題分開,然後再將五個答案分別 code 成 1-5,這才有辦法作分析。
雖說有萬般的不幸,但這資料裡面有個好處:格式差不多。像下面一樣:
問題.=…
今天拿到一個要分析的問卷,不看不知道,一看快昏倒,裡面有一題問卷的回答像下面一樣:
變數裡面全部是 string,這也就算了。一個 string 裡面包含了五個問題,每個問題有五個選項,這還讓不讓人活啊?這樣是沒辦法跑任何分析的,得先將五個問題分開,然後再將五個答案分別 code 成 1-5,這才有辦法作分析。
雖說有萬般的不幸,但這資料裡面有個好處:格式差不多。像下面一樣:
問題.=…
這幾年在美國,剛好有幾次申請加拿大簽證的經驗,所以作一個筆記,免得我這糊塗鬼下次申請時又忘了。
由於我自己是參加研討會,所以是辦旅遊簽證。用加拿大政府的專業術語來說,這叫 temporary resident visa,我作的 checklist 如下。
詳情請見這裡:http://www.canadainternational.gc.ca/los_angeles/imm/visa_temp.aspx?lang=eng#APPLICATION…
今天看到 EndNote 的網站公佈了 EndNote X4 的新增功能,真令人期待啊!感覺才用 EndNote X3 沒多久,新版就出了,有許多不錯的功能。

網友問到:「哈囉,想請教版主有關STATA的問題,如果我想產生一個新變數,而這個變數為另一個變數的累積次數分配,應該怎麼寫此一指令呢?用ta X(變數) 可以得知變數分佈情況,後學所學的指令可能不足,故想請教版主是否知道? 謝謝」
首先,先使用一個資料庫:
sysuse auto, clear
tab 一下結果:
之後先產生次數分配:
bysort rep78: gen freq = _N
檢查一下結果:
list rep78 freq in 1/20

這還只是該值的頻率而已,還不是累積次數分配。如果要作累積次數分配,還得加工一下。
by rep78: gen cumfreq = _N if _n == 1
這一行是說,rep78 每一個值的第一筆資料,cumfreq 的值都設為 rep78那個值的次數。如果是該值的第二筆,那就會設成missing。結果如下圖。

接著下一步,就是把這些值加起來。
replace cumfreq = sum(cumfreq) if !mi(rep78)…

「老師,我的 conceptual framework 有一個 mediator 和一個 moderator……」
我問:「你知道兩個的差別嗎?」
他想了很久:「都是在影響變數之間的關係?」
對了一半。但如果寫進論文,這個「一半」會讓方法段整個站不住腳。
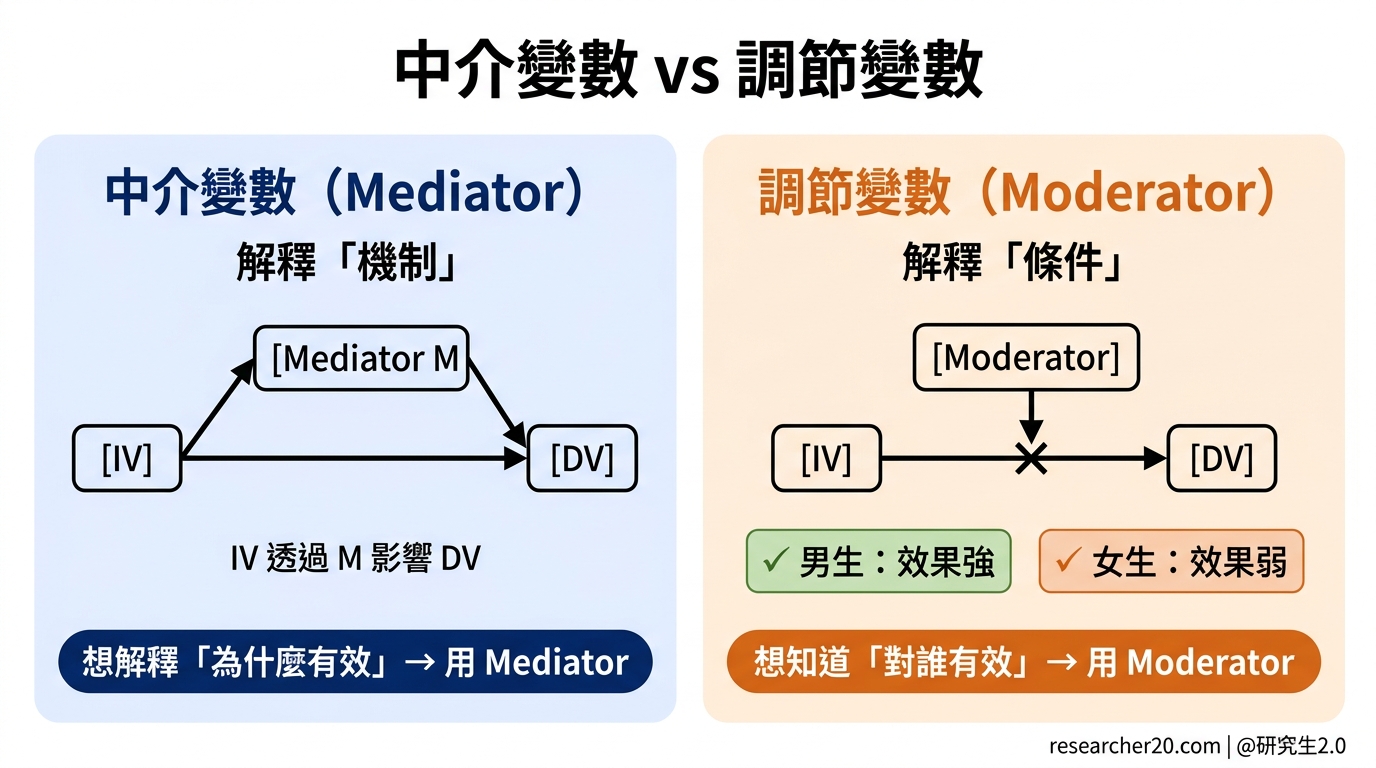
Mediator 回答的問題是:IV 為什麼能影響 DV?透過什麼路徑?
舉個例子:
「降低認知負荷」就是 mediator——它說明了 AI 工具如何影響學習的過程,是 IV 到 DV 的中間橋梁。
簡單說:Mediator 解釋機制,回答「怎麼來的」。
要確認 mediation 是否存在,需要依序確認四個條件:
⚠️ 現代研究多用 Bootstrap 法(如 PROCESS macro)取代 Baron & Kenny 步驟,更直接測試間接效果(indirect effect)的信賴區間。
Moderator 回答的問題是:IV 對 DV 的影響,在什麼情況下更強?更弱?對誰有效?
舉個例子:
「先備知識」就是 moderator——它不解釋機制,而是說明這個效果的邊界條件。
如果你熟悉 ANOVA,moderator 其實就是交互作用(interaction)。
簡單說:Moderator 解釋條件,回答「對誰、在什麼情況下有效」。
Mediator = IV 透過什麼影響 DV(機制)
Moderator = IV 對 DV 的影響在什麼條件下改變(邊界)
你的研究問題就決定了你要用哪個:
這篇被引用超過 40,000 次的論文提供了一個務實的判斷原則:
💡 如果兩者都想研究,就是 moderated mediation 或 mediated moderation,進階但也更完整。
Baron, R.…
中介變數(mediator)與調節變數(moderator):一句話分清楚 Read More »