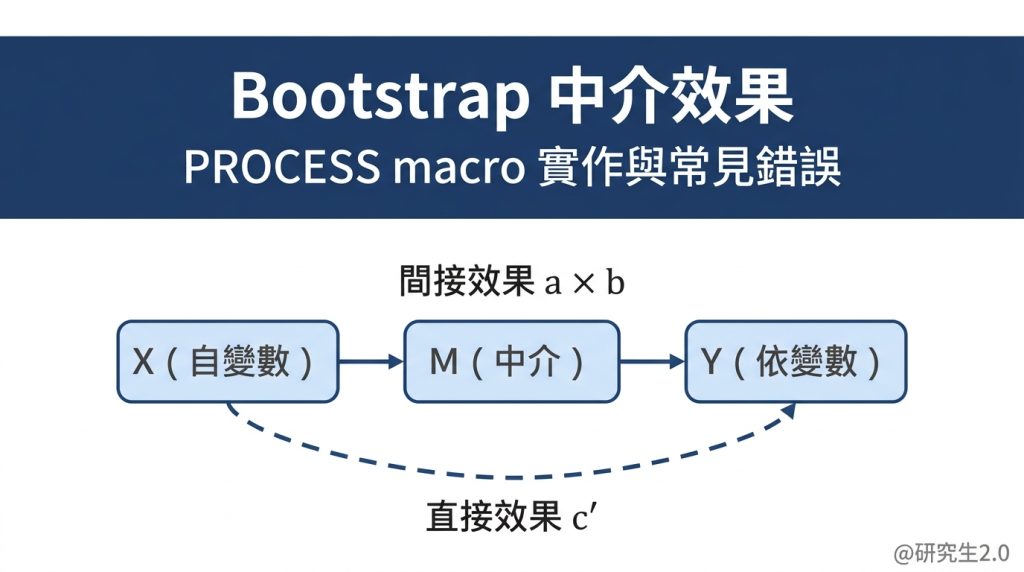
發了三篇頂刊後,我想談談 Profile Analysis 這條研究思路
開場:為什麼我後來幾乎每個研究都會走到 Profile Analysis
我是做教育研究的。這幾年回頭看自己做過的題目,從自我調節學習(self-regulated learning, SRL)、motivation,到 learner differences,雖然表面上研究主題不一樣,但有一件事越來越明確:很多研究計畫走到最後,我都會回到 Profile Analysis 這條思路。
這裡說的自我調節學習,指的是學生能不能自己設定目標、監控進度、調整策略,讓學習不只是被動完成,而是主動管理。
不是因為它比較新,也不是因為它看起來比較厲害。更根本的原因是:教育本質上是人的問題。
教育研究當然可以用很多變項來解釋。你可以看動機高低、策略使用、學習成績、背景變項,也可以做相關、迴歸、ANOVA、SEM。這些方法都重要,也都常用。但如果你真的在研究「人」,你很快就會發現:單一變項本身固然重要,可是真正更有意思的,往往是不同變項之間怎麼組合在同一個人身上。
有些學生不是單純動機高或低,而是動機高但策略弱;有些人策略很多,但監控能力差;有些人表面上總分差不多,可是背後其實是完全不同的 learner type。這些差異,如果只看平均效果,常常會被壓平。
這也是為什麼我後來越來越常用 Profile Analysis。它不是拿來炫技的統計方法,而是一條比較貼近教育問題本質的研究思路。這篇文章想談的,就是:為什麼有些研究做到最後,不能只停在平均數或單一變項關係,而必須進一步去看 profile。
Variable-centered 和 person-centered,問的根本不是同一件事
大部分研究生比較熟悉的,是 variable-centered 的分析方式。
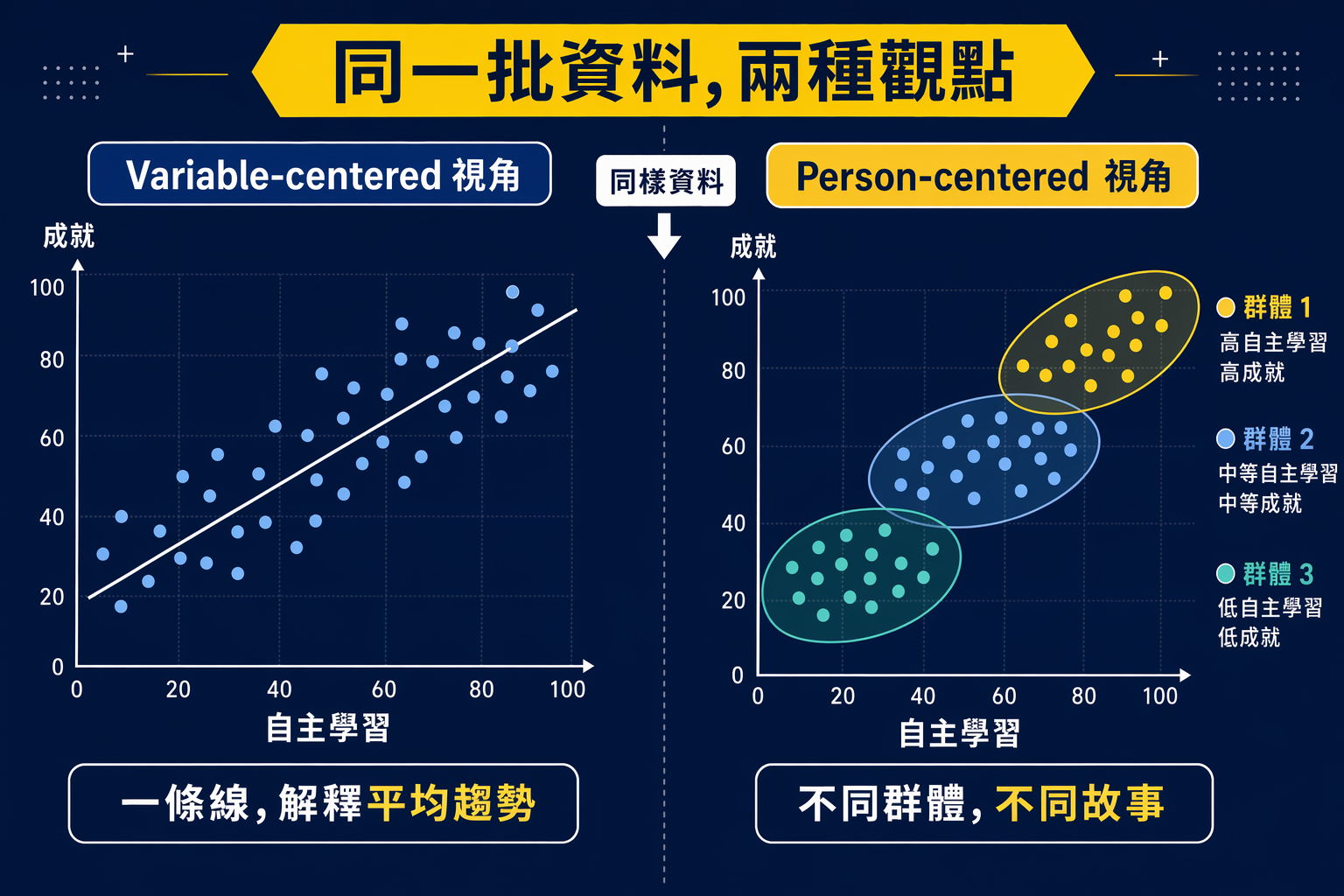
你問的是:
- X 和 Y 有沒有關係?
- 哪個變項可以預測哪個結果?
- 組別之間平均差多少?
這是迴歸、ANOVA、SEM 這一整條分析邏輯最擅長處理的問題。它很好用,也完全合理。很多研究問題,本來就應該這樣問。
但 person-centered 的出發點不一樣。
它問的是:
- 這群人裡面,是不是本來就有不同類型?
- 這些類型之間,各自有什麼特徵組合?
- 不同類型的人,後續表現、結果、風險或需求是否不同?
所以這不是「同一個問題的進階版」,而是另一種問問題的方式。
舉例來說,如果你研究學生的自我調節學習(SRL):
- variable-centered 可能會問:
「SRL 總分能不能預測成績?」
- person-centered 可能會問:
「學生是不是可以分成不同 SRL profile?而且不同 profile 的成績、動機、表現是否不同?」
這兩種做法都可以成立,但它們看到的東西不一樣。
為什麼教育研究特別需要這條思路
在很多教育研究裡,人不是平均數。
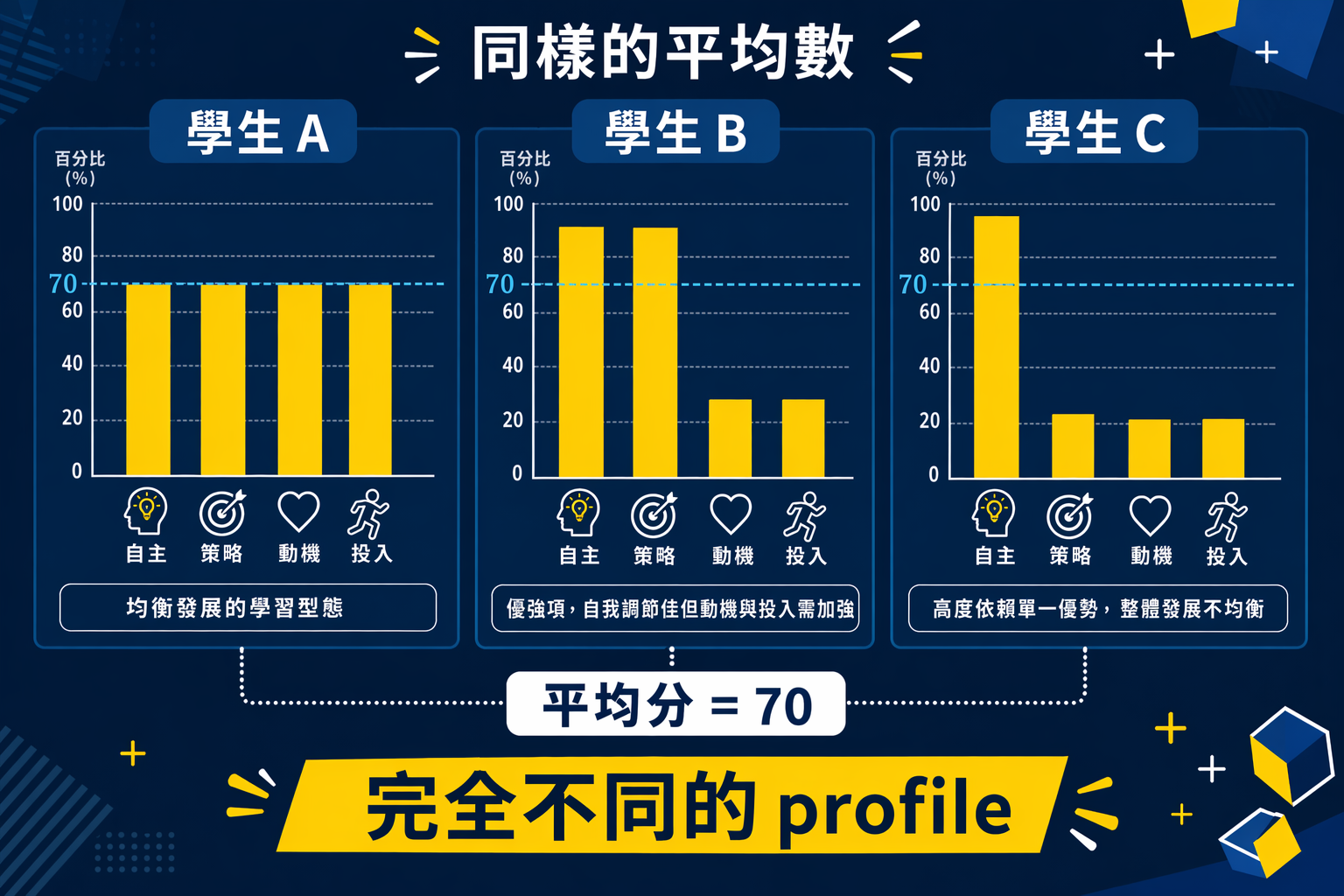
有些學生不是單純高或低,而是「某些面向很強、某些面向很弱」。你如果把這些人全部壓成一個總分,再拿去做相關或迴歸,分析本身可能沒有錯,但你可能已經把最有價值的教育訊息壓掉了。
例如,你研究大學生的時間管理策略,量表有四個分量表:計畫制定、優先排序、執行監控、彈性調整。你把四個分量表加總,然後發現總分和 GPA 相關 .28。
這個分析不是錯,而是不夠。
因為同樣一個總分下面,可能有完全不同的學生:
- 有些人計畫制定很強,但彈性調整很差
- 有些人每個面向都中等,但非常穩定
- 有些人執行監控很強,可是前期規劃很弱
這些人最後在學習表現上可能走向不同結果,但如果你只看一個總分,你就看不見這些差異。
這也是我認為 Profile Analysis 在教育研究裡特別有價值的原因。教育現場真正關心的,往往不是「平均來說這群學生怎麼樣」,而是:這群學生裡面,有哪些不同型態,而不同型態的人需要什麼樣的理解與介入。
Profile Analysis 到底在做什麼
先講最白話的一句:
Profile Analysis 想做的,不是看單一變項的效果,而是辨識人群裡不同的組合型態。
這裡有幾個概念要先分清楚:
1.
…發了三篇頂刊後,我想談談 Profile Analysis 這條研究思路 Read More »