CFA 實作入門:驗證性因素分析步驟與常見錯誤
學生拿著 EFA 的結果來找我,說:「老師,我因素分析跑完了,接下來要跑 CFA 嗎?」
我問:「你為什麼要跑 CFA?」
他愣了一下:「就是…驗證一下?」
這個回答讓我知道,他還沒弄清楚 CFA 是什麼。這也是我想寫這篇的原因——CFA 的概念不難,但實作起來每個步驟都有人反覆在同樣的地方摔倒。
先講一個核心提醒:CFA 不是在證明你的量表一定正確,而是在檢驗你的理論模型是否站得住。 學生最常錯的,不是不會跑,而是把統計決策和理論論證分開了——審稿人最常抓的,也正是這個斷裂。
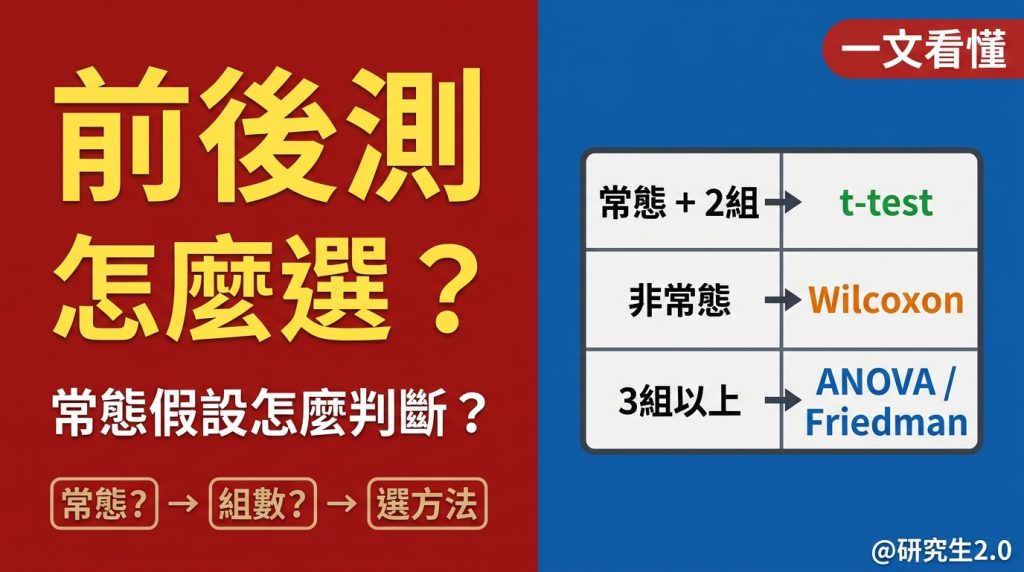
CFA 是什麼?跟 EFA 有什麼不同?
探索性因素分析(EFA)是在「不確定結構」的情況下使用的——你不確定有幾個因素、哪些題目應該歸在一起,所以讓資料自己告訴你。
驗證性因素分析(CFA)完全相反。你已經有一個明確的理論模型,然後用資料去驗證這個結構跟實際資料的配適程度。
CFA 的前提是:你有理論依據。 最常見的誤用是先跑 EFA 找出因素結構,再用同一份資料跑 CFA「驗證」——你用資料找出一個結構,再用同一份資料確認它,這叫過度擬合,不叫驗證。我看過不少論文這樣做,審稿意見也常常在這裡被抓到。
CFA 實作五步驟
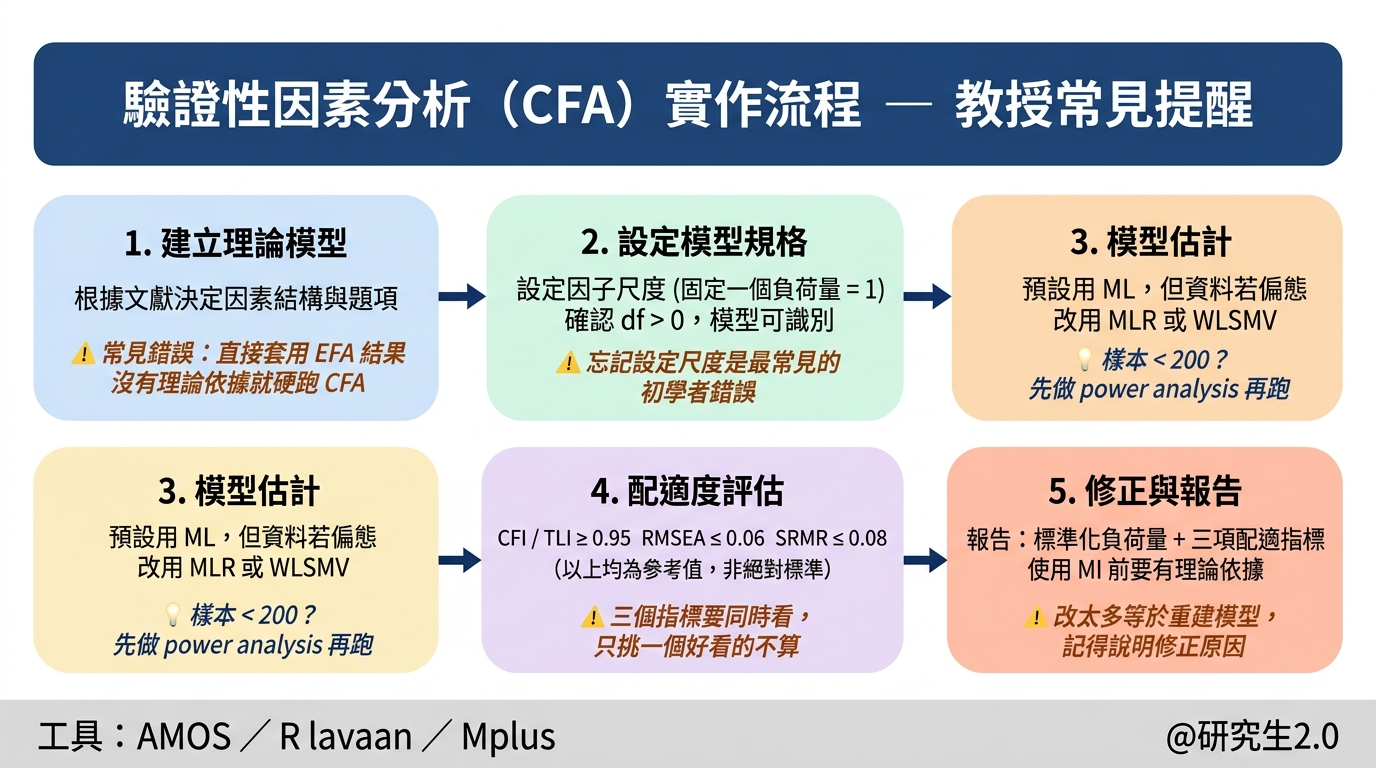
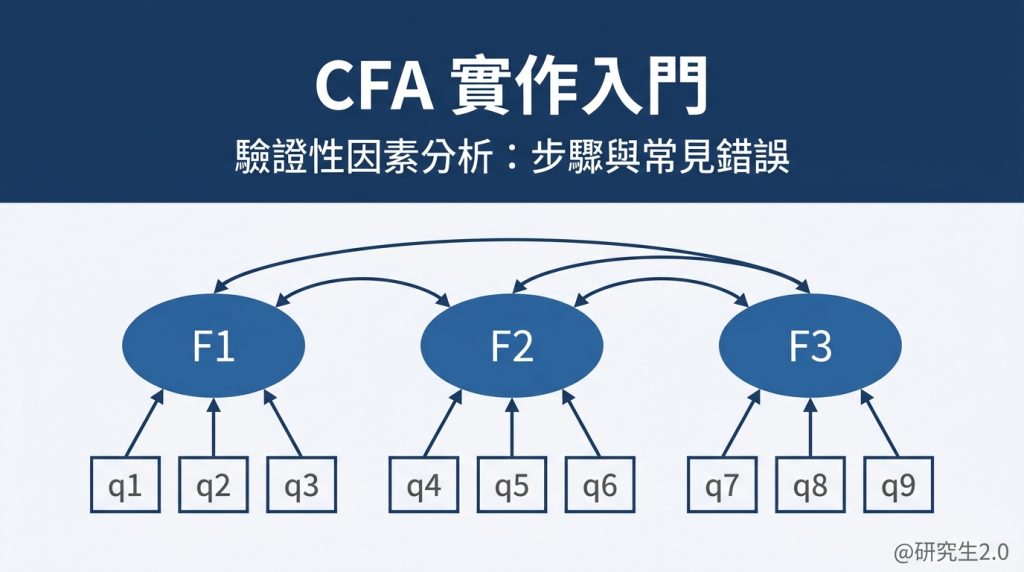
步驟一:建立理論模型
在正式跑分析之前,先把測量模型畫在紙上。你需要清楚指定:幾個潛在因素、每個因素對應哪些題項、因素之間是否允許相關、有沒有 cross-loading。
這個步驟很多學生跳過,直接打開 AMOS 開始畫。但跳過這步的學生,在後面遇到問題的時候,通常不知道問題出在模型設定還是資料本身。先把模型畫在紙上,思路會清楚很多。
在畫模型之前,我會要求學生逐題問自己:「這一題為什麼只能屬於這個因素,不屬於別的?」 這個問題問得清楚,後面很多麻煩就不會出現。
容易犯錯的地方:
- 每個因素的題項數不夠。 我常看到學生把一個因素只放兩題,說「文獻原版就是這樣」。問題是兩個題項的因素在統計上無法識別(just-identified),連配適度指標都算不出來。最少要三題,建議四題以上。如果原始量表某個分量表真的只有兩題,需要在方法段說明並討論限制。
- 跨文化量表直接套用原版因素結構。 學生拿英文量表翻成中文,就直接假設結構不變。翻譯後的題項語意可能已經不同,嚴格來說應該先用新的資料跑 EFA 確認結構,或至少在論文裡說明這個限制。
- 構念邊界不清。 審稿人最常抓的是:某些題項文字看起來同時可屬於兩個因素,前面不先處理,後面 MI 和 cross-loading 會一直爆。
步驟二:設定模型規格
在 AMOS 裡,你在圖形介面畫橢圓(潛在因素)和方框(題項),用箭頭連起來。在 R lavaan 裡,用 =~ 語法定義:
f1 =~ q1 + q2 + q3 + q4 f2 =~ q5 + q6 + q7 + q8 f3 =~ q9 + q10 + q11 + q12
模型畫完還有一件必須做的事:固定因子尺度。 潛在因素本身沒有測量單位,需要人為固定一個尺度,模型才能估計。兩種做法:
- 固定一個負荷量為 1(marker variable): AMOS 和 lavaan 預設。每個因素的第一個題項路徑固定為 1。
- 固定潛在因素的變異量為 1: 讓所有負荷量都自由估計,適合要比較不同題項貢獻時。lavaan 語法:
std.lv
CFA 實作入門:驗證性因素分析步驟與常見錯誤 Read More »