
Literature Review 怎麼寫才不爛?避開摘要流水帳的實作流程
寫 thesis proposal 或論文第二章時,最常被教授打槍的問題是什麼?
不是文獻讀得不夠多,是讀完之後寫成了高級摘要集。A 學者說了什麼、B 學者發現了什麼、C 學者的結論是⋯⋯寫到最後,讀者只知道你讀了 30 篇 paper,但看不出這 30 篇跟你的研究有什麼關係。
這篇的目標很簡單:給你一個可執行的 workflow,從「開始搜尋」到「寫出段落」,避免把 literature review 寫成逐篇摘要。
六步流程:從搜尋到段落
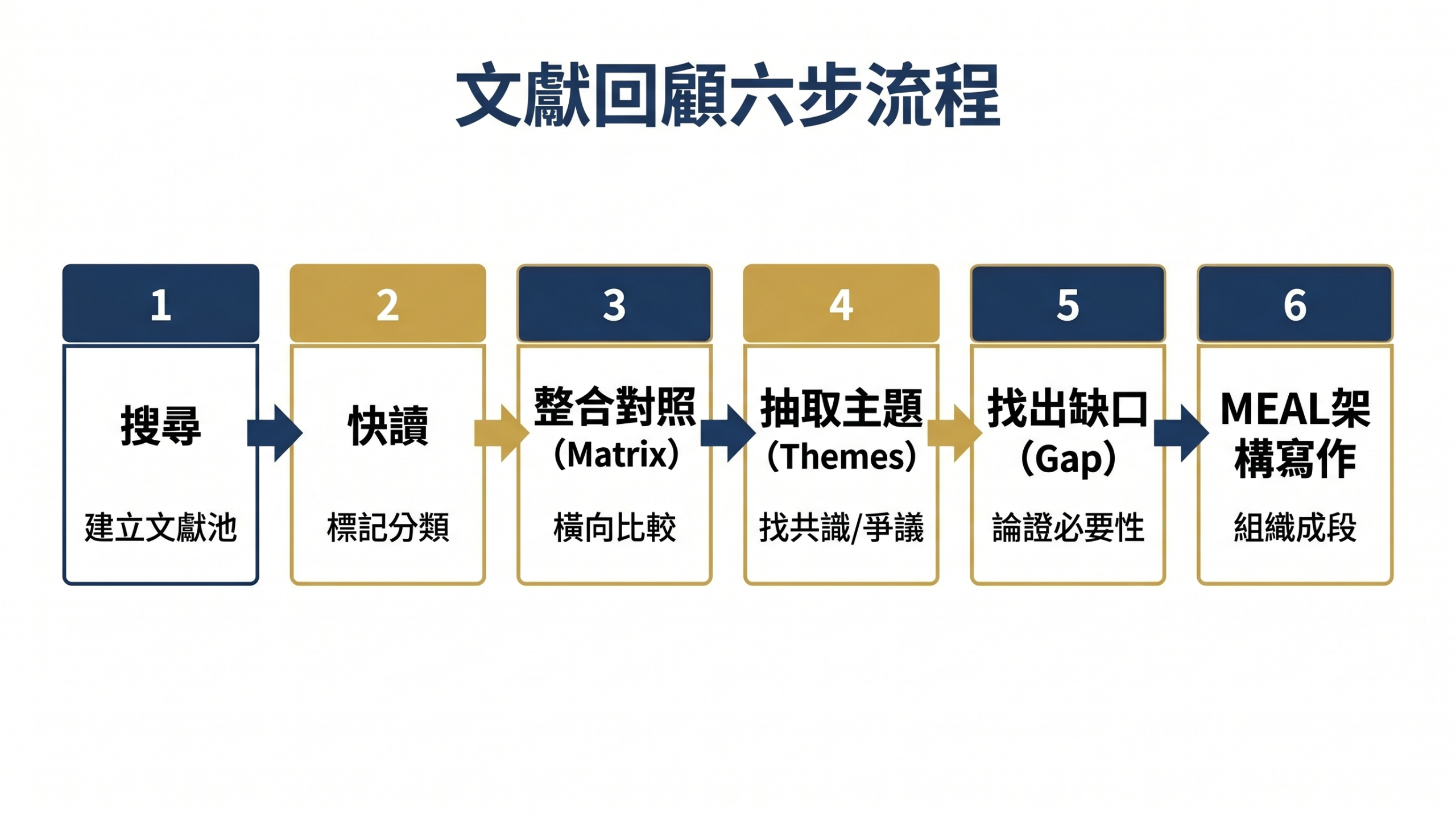
Step 1:搜尋與初步篩選
先承認一件事:你不可能讀完所有相關文獻。重點是建立一個「夠用且可管理」的文獻池。
實際操作:
- 從 2-3 篇該領域的權威 review article 或 meta-analysis 入手,抓出核心概念與關鍵字
- 用關鍵字在 Scopus / Web of Science / Google Scholar 搜尋,設定時間範圍(建議近 10-15 年為主,標誌性經典除外)
- 第一輪篩選看 title + abstract,只保留「可能相關」的,不要糾結當下判斷是否準確
- 目標:建立一個 30-50 篇的「待讀清單」,之後會再縮減
常見錯誤:搜尋階段就過度篩選,或糾結「這篇到底要不要讀」而卡住。先抓進來,step 2 再判斷。
Step 2:快讀與分類標記
這階段不要逐字讀。用「快讀 + 標記」建立文獻的初步定位。
實際操作:
- 每篇控制在 15-20 分鐘:讀 abstract → 掃 introduction 最後一段(研究目的)→ conclusion
- 在 reference manager(Zotero、EndNote、Mendeley)裡加標籤:按主題(
#認知負荷、#遊戲化學習)、按方法(#實驗法、#質性訪談)、按立場(#支持 X 理論、#質疑 X 理論) - 同時記錄:這篇的研究對象、主要發現、方法限制(用簡短 keyword,不要完整摘要)
重點:這階段的筆記是「給搜尋用的」,不是給寫作用的。目的是讓你之後能快速找到「有哪些文獻講了這個主題」。
Step 3:建立 Synthesis Matrix
這是從「摘要模式」切換到「綜合模式」的關鍵步驟。Synthesis Matrix 是一張橫向比較表,讓你看到「關於某個概念,多篇文獻各自說了什麼」。
| 作者 (年份) | 研究對象 | 核心發現:X → Y 的關係 | 方法限制 | 與本研究的關聯 |
|---|---|---|---|---|
| Chen (2020) | 大學生 | 正向但微弱 (β = .12) | 橫斷式設計 | 需要縱貫驗證 |
| Wang (2021) | 高中生 | 調節效果:動機為 moderator | 樣本僅台北 | 可擴展到南部 |
| Lin (2022) | 在職進修 | 無顯著效果 | 自我回報量表 | 可能測量誤差 |
為什麼不用傳統摘要?傳統摘要是你對著單篇文獻寫「這篇說了什麼」;Matrix 是讓你橫向看「這幾篇對同一個議題有什麼不同說法」。後者才能幫你找 pattern。
工具建議:Excel、Google Sheets、Notion database 都可以。重點是「能橫向比較」,不是用什麼軟體。
Step 4:從 Matrix 抽出 Themes
讀完 Matrix,下一步是問:這些文獻能歸成幾個主題?不是問「有哪些作者」,是問「有哪些論述脈絡」。
抽 theme 的三個判準:
- 共識區(Consensus):哪些觀點是多方支持的?這構成你文獻回顧的「背景共識」段落。
- 爭議區(Controversy):哪些議題有對立觀點或矛盾結果?這是文獻回顧的「對話核心」,也是你展現批判性思考的地方。
- 缺口區(Gap):哪些重要問題還沒被充分回答?這直接導向你的研究問題。
實例:不是「A、B、C 都研究了認知負荷」,而是「關於認知負荷的測量,目前存在兩派:客觀生理指標派 vs.…
Literature Review 怎麼寫才不爛?避開摘要流水帳的實作流程 Read More »




