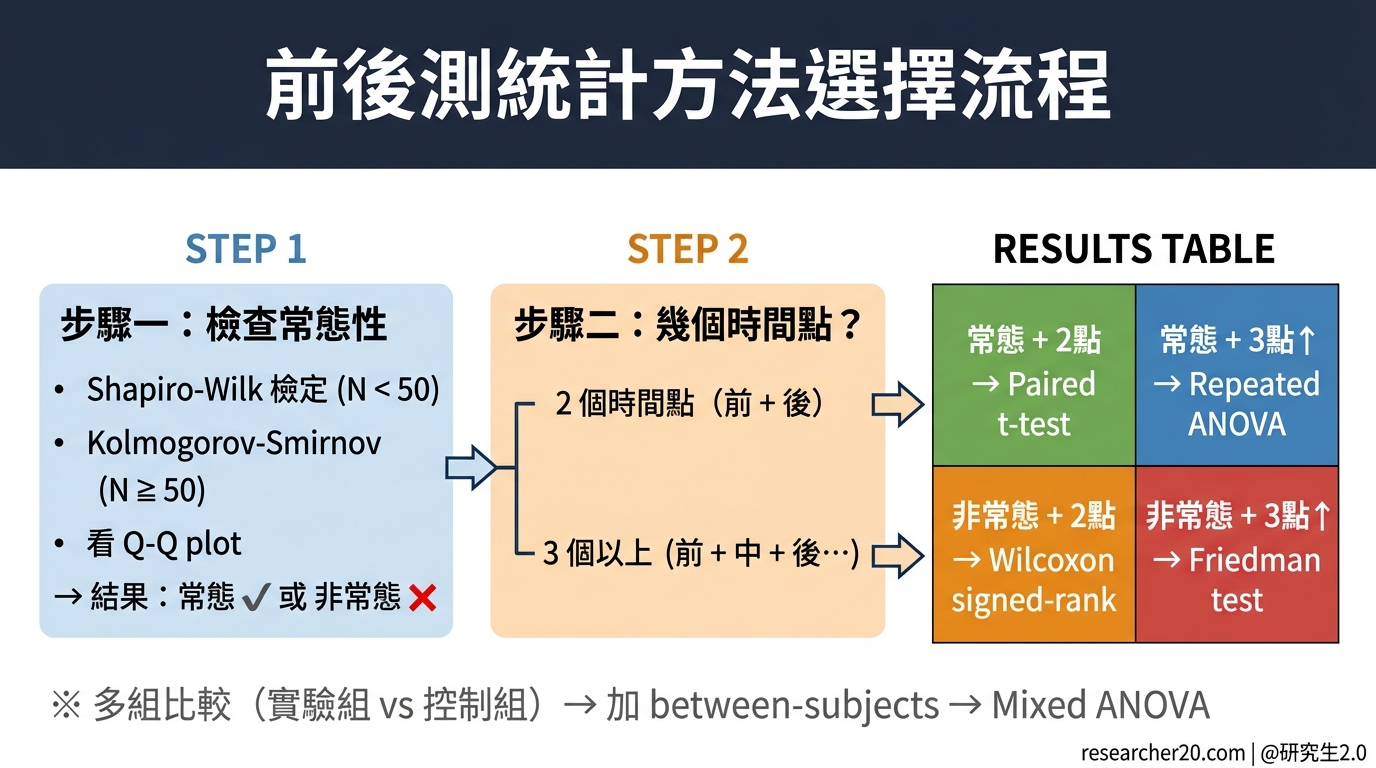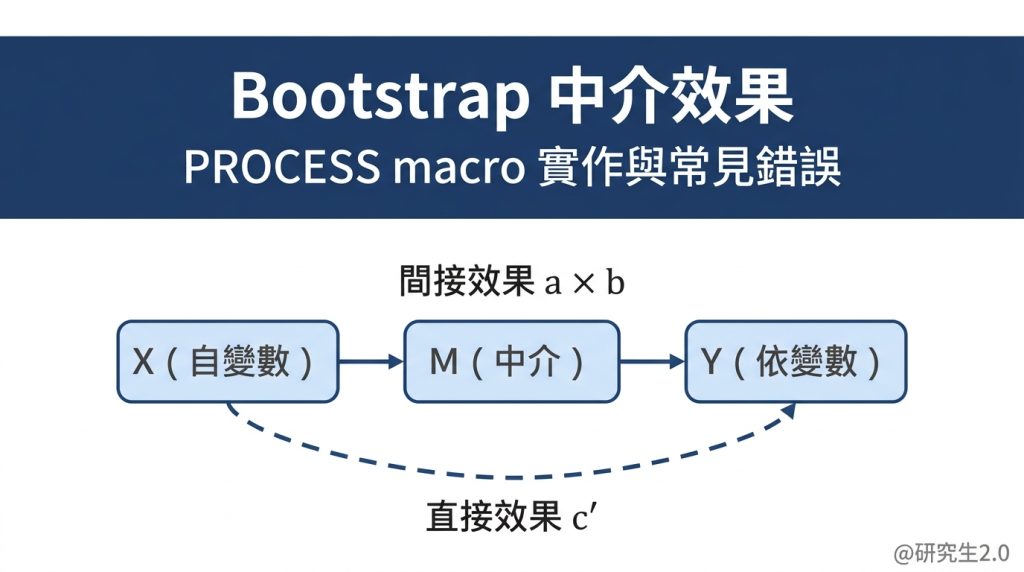
Bootstrap 中介效果:用 PROCESS macro 跑比 Baron & Kenny 更準
我指導過不少論文,有一個問題學生最常問:「老師,我用 Baron & Kenny 四步驟做中介分析,夠嗎?」
我的回答通常是:「在教育、心理、管理等領域,bootstrap 間接效果檢驗已經非常普遍,很多期刊和審稿人會期待看到。如果你還只用四步驟,很可能被要求補做。」
這篇從為什麼要改、怎麼跑、怎麼報告,一步一步說清楚。
先釐清一個學生最常有的誤解:中介分析不是在問「X 對 Y 還有沒有影響」,而是在問「X 是否透過 M 影響 Y」。 這個方向搞清楚,後面的邏輯才會通。
Baron & Kenny 四步驟,問題出在哪?
Baron & Kenny(1986)的四步驟中介檢驗,被引用超過 40,000 次,是教科書裡最常見的方法:
- X → Y 顯著(總效果 c path)
- X → M 顯著(a path)
- M → Y 顯著(b path,控制 X)
- 加入 M 後,X → Y 的效果減小或不顯著(中介成立)
這個方法的根本限制是:它用逐步顯著性來推論中介,而不是直接測試間接效果(indirect effect = a × b)的大小。
問題在於:a 顯著、b 顯著,不代表 a × b 顯著。反過來,a 或 b 個別不顯著,但 a × b 可能仍然顯著。這不是邏輯問題,是統計問題。
Sobel test 試圖直接測試 a × b,但它假設間接效果的抽樣分佈是常態的。而現實中,間接效果的分配往往是偏斜的(skewed),因此 Sobel test 在小樣本或中等樣本下容易過於保守、統計力不足,導致本來存在的間接效果被漏掉(Type II error)。
⚠️ 容易犯錯的地方:很多學生看到「X → Y 不顯著」就直接放棄做中介分析。但現代中介分析的觀點是:total effect 不顯著,仍然可能存在顯著的間接效果。X 可能透過 M 正向影響 Y,同時又有另一條路徑直接負向影響 Y,兩者抵消讓總效果看起來不顯著,但中介機制確實存在。
Bootstrap 的邏輯是什麼?
Bootstrap 不依賴間接效果分配是常態的假設,而是直接從你的資料出發,用重複抽樣建立信賴區間。邏輯如下:
- 從原始樣本中,重複有放回地隨機抽樣(通常 5000 次)
- 每一次都計算間接效果 a × b
- 把 5000 個 a × b 的值排序,取第 2.5 百分位和第 97.5 百分位,作為 95% 信賴區間(BootCI)
- 如果 95% BootCI 不包含 0 → 間接效果顯著
相較於 Sobel test,bootstrap 不依賴間接效果常態分配假設,更適合處理偏斜的間接效果分配,通常也有較佳的統計力。方法學文獻普遍建議以 bootstrap 信賴區間作為間接效果的主要檢驗方式,許多期刊也明確期待看到這種做法。
⚠️ 一個細節:PROCESS macro 提供兩種 bootstrap CI:percentile CI(直接取百分位)和 bias-corrected and accelerated CI(BCa,修正偏誤)。一般情況下 percentile CI 已經夠用,但如果間接效果分配明顯偏斜,BCa 更準確。PROCESS 預設是 percentile,若要改成 BCa 可在選項中設定。在論文裡報告時,說明你用的是哪種。
用 PROCESS macro 跑 Bootstrap 中介
Hayes 的 PROCESS macro 是目前最廣泛使用的工具,免費,支援 SPSS 和 SAS。
安裝:到 processmacro.org…
Bootstrap 中介效果:用 PROCESS macro 跑比 Baron & Kenny 更準 Read More »