
每次要分析資料,你是不是也有這種時刻——
數據都整理好了,軟體也開了,手指懸在鍵盤上,然後……腦子空白。😶
「這題該用 T-test 還是 ANOVA?」
「前後測可以用 T-test 嗎?」
「什麼時候才需要用 Regression?」
這篇文章不講公式,不推導原理,只告訴你什麼情況用什麼方法。
t 檢定(T-test):比較兩組的平均值
T-test 的核心問題只有一個:這兩組的平均值有沒有差異?
使用條件很單純:有兩組,而且只有兩組。組別必須是類別變數,像是性別(男/女)、實驗組與控制組、有無接受訓練。
⚠️ 如果超過兩組,就不能用 T-test,要換 ANOVA。原因很簡單:每做一次 T-test,犯錯機率就疊加一次。三組硬拆成三次 T-test,整體錯誤率早就超標。
還有一個很常犯的錯誤:把前後測資料當兩組獨立樣本跑 T-test。
前後測是同一批人測兩次,兩筆分數之間有關聯,這種情況要用的是 paired-sample t-test(配對樣本 T 檢定),不是 two-sample T-test。用錯了,結果就算顯著,也不代表你真正想證明的那件事。
延伸閱讀:如何分析前後測:進步分數 / 殘餘改變分數
One-way ANOVA:三組以上的平均值比較
只要你的組別超過兩組,就換 ANOVA。
One-way ANOVA(單因子變異數分析)的邏輯跟 T-test 一樣,都是在問「各組的平均值有沒有差異」,只是 ANOVA 可以同時比較三組以上,只做一次檢定,不疊加錯誤率。
例如:想看不同教學法(A、B、C 三組)對學生成績的影響,就用 One-way ANOVA。
⚠️ ANOVA 只是「全局檢定」,不是終點。
ANOVA 檢驗的假設是:
- H₀:所有組的平均值都相同
- H₁:至少有兩組的平均值不一樣
問題在這:ANOVA 只告訴你「有差異」,但不告訴你是哪兩組不一樣。
所以如果 ANOVA 的結果顯著(reject H₀),接下來還需要做 pairwise comparison(事後比較),逐一比較各組之間的差異,再搭配 p-value 校正(如 Benjamini-Hochberg 或 Bonferroni),避免因為多次比較而膨脹 Type I error。
簡單說:ANOVA 顯著 → 知道有差異 → pairwise comparison → 知道哪裡有差異。
Two-way ANOVA:同時看兩個類別變數的影響
如果你有兩個類別變數(例如:性別 × 教學法),想同時看它們對結果的影響,就用 Two-way ANOVA(雙因子變異數分析)。
Two-way ANOVA 還可以幫你看交互作用——也就是「不同性別在不同教學法下,效果是否有差異」這種問題。
Multiple Regression(線性回歸):多個變項如何影響結果
Regression 的核心問題是:這些變項,各自對結果有多大的獨立影響力?
和 T-test/ANOVA 最大的不同在於:Regression 讓你同時放入多個變項,在控制其他變項的條件下,估計每一個變項對結果的影響。這讓你可以回答更精細的問題,例如:「在控制了家庭背景之後,教學法對成績的影響還顯著嗎?」
另外,很多人以為 Regression 只能用在連續變項之間,其實類別變項轉成 dummy variable 一樣可以丟進去。延伸閱讀:什麼是虛擬變量?
ANOVA 跟 Regression,到底差在哪?🤔
這是很多人的疑問。直接說:ANOVA 其實是 Regression 的特例,兩者底層是同一套數學。
差別只在於:ANOVA 的自變項是類別變數;Regression 通常是連續變數(或 dummy variable)。如果你跑 ANOVA 和 Regression(用 dummy variable),結果會是一樣的。只要懂了這個,初、中級的統計就沒什麼問題了。
卡方檢定(Chi-square):比的是比例,不是平均值
前面所有方法比的都是平均值。卡方檢定比的是比例。
使用時機:你的變項是名目變數(nominal variable),想知道某件事在各組發生的比例是否相同。
例子:男女在「是否吃素」這件事上,比例有沒有差異?→ 卡方檢定。✅
⚠️ 注意:卡方檢定的變項不能是連續變數或 ordinal variable,必須是「是與否」、「男與女」這種名目變數。
一張表,快速對照 📊



一張圖看懂 📊
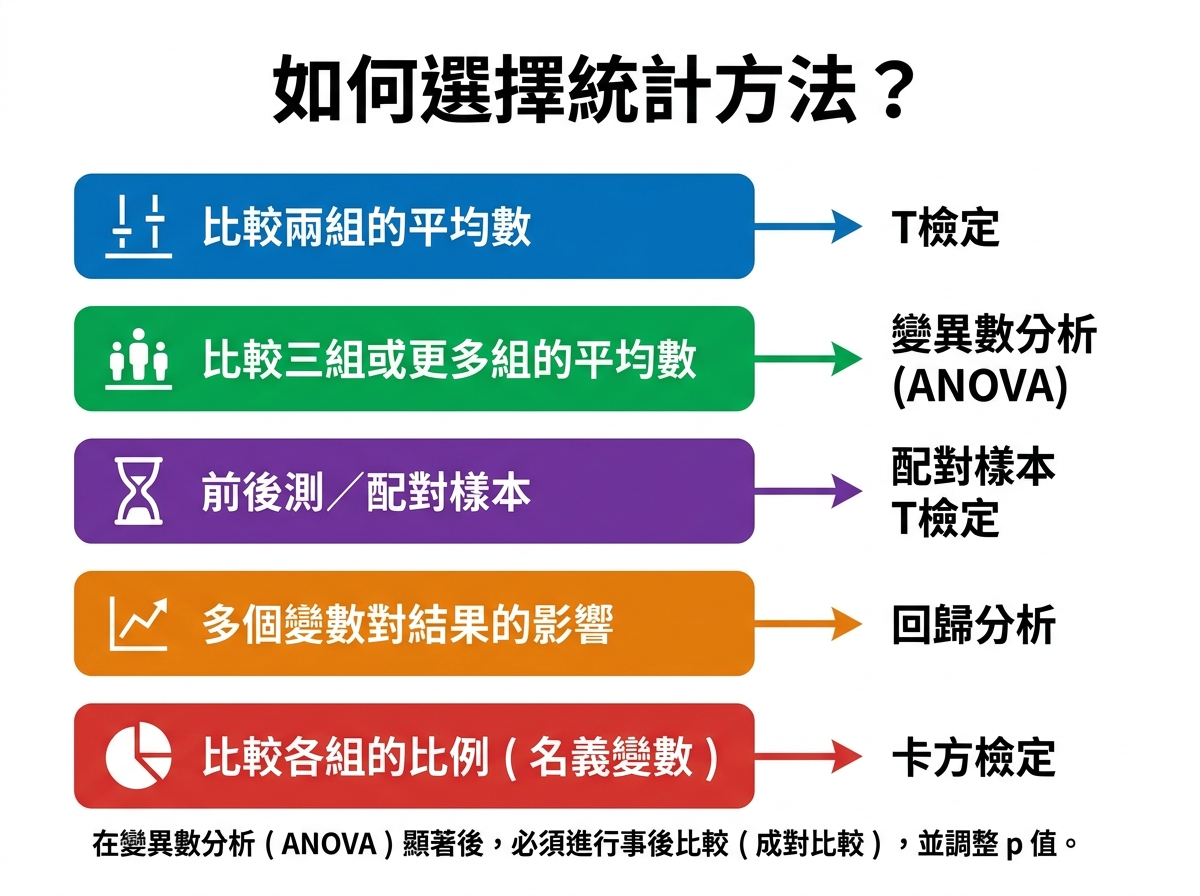
懶人決策流程 👇
不確定要用哪個?照這個流程走:
📌 你想比較的是「平均值」嗎?
→ 兩組 → T-test
→ 三組以上 → ANOVA
→ 前後測 / 配對樣本 → Paired T-test
📌 你想知道多個變項如何影響結果?
→ Regression(類別變項先轉 dummy variable)
📌 你比的是「比例」,而且變項是名目變數?
→ 卡方檢定
💡 如果你想看這個主題的精簡版,我最近在 Threads 整理了一個系列,從痛點出發、逐步拆解:用哪種統計方法好?(Threads 系列)
如果有任何問題,歡迎留言討論。😊
更新記錄:
2009/4/17 補充外部參考資源
2011/11/18 修正前後測說明(感謝川爸指正)
2017/9/18 加入副標題與 Multiple Regression 說明
2026/3/18 全文改寫:重新整理說明邏輯、加入決策流程、補充 Regression 多變項本質
簡單的說,卡方檢定的適用範圍最廣,尤其是自變數跟依變數尺度、類別不同時,只要有列聯表、cross table就可以用,所以有卡方一致性檢定、獨立性檢定等,需注意的是如何找出cell和cell之間的關聯需要更進一步的判斷,不單只看卡方值或顯著性;
t-test和Anova可以看成是同一組的,都是檢定依變數在自變數上的表現 差異 ;
迴歸則是在檢定 影響性 ,這是最被研究者詬病的,因為有可能GIGO,變數的方向性是研究者賦予的。
謝謝你留言補充,不過我不完全同意。統計沒什麼「適用範圍最廣」,主要是看你要測什麼,有什麼,對吧?如果你只有一個categorical variable,但多個continuous variables,也不能用卡方,是吧?
其它部分你說得比我好。「差異」就是圖表裡的comparision of means,平均之間的不同,就是差異。
「影響性」是說association,是看自變數和依變數之間的關係。
再次謝謝你的補充!
您說的沒錯,我忘了考量會碰到continuous variables的狀況,因為身邊碰到的調查工作,要碰到continuous variables的情況還真不多 XD
用proportion,mean,association來做區別到也是個很好的判斷方式,再次感謝您的分享~
請教重複測量與時間序列如何作?我總共前測與後測四次!
repeated measures跟ANOVA應該是你需要的關鍵字,複雜一點可能要看MANOVA
我知道的不多,但希望對你有幫助
重複測量的長期趨勢分析還是用GLMM來做比較好。MANOVA沒有辦法考慮到時間的自相關性啊~
前後測隨機控制實驗(pretest-posttest randomized controlled trials),常被採用探討介
入方案之介入效果(intervention effect)。請問使用後測結果(posttest data)做組間
比較是否比前後測差異(Pretest and posttest difference, or gain data)在組間做比較,
統計檢定力(statistical power)差?如果是,是什麼情況之下?如果不是,又是什麼
情況之下?
這題該如何解答? 懇請賜教
以TwoWay fixed effects ANOVA 為例,請說明Type I sum of squares and Type III sum of squares,在unequal cell sizes 情形下,兩種sum of squares 不同,請問就主效用(main
effects)的檢定,兩者檢定的虛無假說(null hypothesis)有何不同?
請統計學高手幫忙? 感激不盡
這兩題我怎麼看都像是作業耶,我好像沒有幫人家作作業的習慣..
以後要問這類問題,先說出你的看法吧!不然我就會說我不懂,直接無視了…
這兩題不是作業, 是考題, 想弄懂它, 是真的不會, 也查了一些書, 還是不懂他在問什麼, 所以才想請教統計方面觀念較清楚的大大, 真抱歉
type I and type III sum of squares你可參考wiki:http://en.wikipedia.org/wiki/Explained_sum_of_squares
要詳細一點可看SAS別人寫的annotated output:
http://www.stat.sc.edu/~habing/courses/516sossup.pdf
若是data是李克特量表的型態, 且都是呈非常態分配(以1-7點而言, 大部份結果都分佈在4,5,6, 且經由k-s test和shapiro-wilk test檢定結果是非常態分配), 請問是否可以用logistic regression 來分析? 研究問題: 何種因素會影響顧客滿意度. 問卷的問題(因素)都是參考/截取之前的文獻.
或是有什麼統計方法可以解決? 謝謝
如果你是有一堆問題(假設100題)是關於滿意度的,但你想要找出5點最重要的,那你要用的就是因素分析 factor analysis。
Logistic regression要結果是0或1的值才能,這似乎不適用於你目前的情況。
謝謝
我是把所有的因素都做了因素分析
舉例而言,
從total 100個因素中, 頡取了15個因素
再用這15個因素預測哪些會造成顧客整體滿意度,
整體滿意度在原始問卷中也是使用1-7點李克特量表
但為了要跑羅吉斯迴歸,我把整體滿意度的答案重新編碼, 1-4編為0,表示是low satisfaction, 而 5-7編為1, 表示是 high satisfaction
請問這樣會有什麼問題嗎?
或是有任何文獻也是使用類似的編碼, 各位前輩可以share?
謝謝
@PPWPY,
有一個明顯的問題就是你壓縮了原本的variance,這樣可能會高估或低估你的結果。
雖然我不知道你為什麼用logistic regression,但我覺得你好像應該用SEM來做。你可以參考這篇:http://newgenerationresearcher.blogspot.com/2009/01/what-is-structural-equation-model.html
多謝你
不過為什麼會是 '壓縮'呢?
可能我沒有表示清楚吧, 所截取的15個因素是factor analysis的結果,
而所有data也如上面所說, 都呈非常態分配
一般要做預測的分析, 好像都是跑迴歸居多
可是只有ligistic regression 可以接受是非常態的資料, 所以這是為什麼我想用logistic regression 的原因
另外, 想請問你, SEM接受非常態的資料嗎?
謝謝
作者已經移除這則留言。
@PPWPY,
我所謂壓縮variance,就是你原本的variance可能從0-6變成0-1了,這可能會影響到你的結果。
Regression的兩大用處是prediction和explanation,你可參考這篇:http://newgenerationresearcher.blogspot.com/2009/04/what-is-multiple-linear-regression.html。所以不管你是用multiple regression、logistic regression或是SEM,都可以作一些預測。
我會建議用SEM是因為你如果想要看這些因素會不會影響到你的客戶滿意度,如果你用multiple regression或logistic regression,沒辦法處理因素之間的correlation,所以用SEM結果會比較準確&漂亮。
"要先記得,卡方檢定的變數不是連續變數,也不是類別變數,而是名目變數(nominal variables),也就是「是與否」、「男與女」這種變數。" This sentence is a little confused since 類別變數(categorical variables) and 名目變數(nominal variables) are the same.
oops! 感謝指正!
您好!想請教您
如果我要做的是比較兩個GROUPS的環境設計,照顧人力配置,活動設計,日常生活照顧
對這兩個GROUPS母群體的問題行為發生頻率有無差異
我要用的統計方式是?
謝謝您!!
您好,想請教問題:
因為有點不太知道
倘若樣本數為30以下,為了考驗其可靠性、穩定性及一致性,須做項目分析、信度分析或效度分析,請問該用什麼統計方式做分析呢?
謝謝
請問如果是兩組樣本
可以用Anova來分析
還是一定要用t檢定??
當然可以用anova,結果應該是一樣的
我想請問該如何解釋"卡方"
因為我做了Logstic迴歸分析後,有出現"卡方"這個名詞
您好:
我想請問ANCOVA是不是就等於直線迴歸+DUMMY???
@LIU,
是的。如果是full model,要加上interactions
作者已經移除這則留言。
文中提到「另外,常犯的錯就是把前、後測是否有顯著差異用T-test來檢定。即使有兩組,前、後測也不是用T-test來檢定的,更別說有人「假裝」把前測當一組,後測當一組,拿來做T檢定。」
請參看:
http://www.wellesley.edu/Psychology/Psych205/pairttest.html
http://www.stattutorials.com/EXCEL/EXCEL_TTEST2.html
如何用 paired sample t-test (當然不是 two samples t-test) 比較同一母體的前後測結果。
感謝川爸指正,原文已更新,還請川爸再看一眼是否正確。如果其它文章有錯誤,還請不吝指正!感激不盡!
我的論文要檢定干擾效應:來源國家干擾 品牌權益跟購買意願的關係。來源國跑出來一個因素,品牌權益3個因素,購買意願1個因素。那請問要用那種分析法來檢定來源國有沒有干擾效應?並如何進行?
非常感謝您們的協助!
@I.T.
i think it's not confusing. 'cause both nominal and ordinal variable could be called as categorical variable.
常犯的錯就是把前、後測是否有顯著差異用two-sample t-test來檢定,不能「假裝」把前測當一組,後測當一組,拿來做two-sample T檢定,而是應該用paired-sample t-test來檢驗是否有差異。
I think this issue should depend on which way the researcher inputs the data, if
Treatment performance
Before 78
Before 89
After 67
After 89
We still can use two-sample T,
But if the researcher inputs data like
Before after
78 67
89 89
We should use paired-sample t-test
This is my shallow understanding, hope to hear you feedback
最近在分析實驗數據使用到卡方分布,藉由調變卡方分布的自由度來吻合我的實驗數據,但其中卡方分布的自由度要調到小於一的真分數才可以跟我的實驗數據匹配,我查過統計的書本,卡方分布的最基本定義其自由度是一個整數;查過相關的論文,如果是分數的話,也是大於一的分數有數學上的證明;即使實驗數據能吻合,但我很難給他物理上的詮釋,我本身不是統計出身,也不確定這樣可不可行;所以我想請問大家有沒有遇過真分數的自由度,其物理意義是什麼?或者我可以把它當成一個新的模型來用?
您好,我想請問一下:
我做的知識測驗共分為前後測,而我想知道前後測的結果是否有顯著地改變。因為我的題目僅有分為"正確與錯誤",即其為名義變數,這樣感覺上應採用卡方檢定。但我查到關於卡方檢定之資料皆為"獨立性檢定或適合度檢定",並未提到檢測名義資料的差異,然前後測必是相關資料,且檢定出來的結果p值皆<.001,這樣到底表示前後測有顯著改變?又或表示前後測為高度相關?我對這個結果真的感到很困惑,想請您為我解惑,萬分感激。
@keyun chen,
請問你的前、後測只有一題嗎?還是有多題?
您好,我的前後測有多題,只是我想看單題的情況,所以才想知道卡方檢定是否可以這樣做。
另外很抱歉我這麼晚才回…真的萬分抱歉,真的很感謝您的回覆。
請問一下,我用卡方檢定分析某因素和某疾病的關聯性,因為性別有可能是confounder,那要如何adjust性別呢?
@keyun chen,
前後測有多題,整體分析就應該加總起來。
如果看單題,我還真的不知道該怎麼測。問問晨晰的顧問看看吧!
@wwwcktw,
你可以用logistic regression嗎?我不太確定為什麼非得用卡方,而不能用logistic regression。
2. 請問汽車製造地區(A,B,C,)與汽車汽缸數(3,4,5,6,8)是否有關聯?
3. 請問汽車引擎排氣量與汽車省油程度MILES/PER;汽車引擎排氣量與馬力之關聯性為何?
4. 請問美國地區製造的汽車其汽車引擎排氣量與汽車省油程度之關聯性為何?
請問這些題目應該用甚麼分析?
赞
請問一下如果資料為單變量常態 要怎麼辦?
怎麼修正
如過能救我 感激不盡
您好 我是該畢業的研究生了 卡在統計跟spss一陣子了
我想請教大家 假如有四個群組跟22對形容詞語彙
我想要得知哪個語彙會是得到哪一個群組
這樣我該用怎樣的方式比較恰當?
我所分析的資料未符合 "常態分配" (非常態分配),請問還能用迴歸分析嗎? 哪一種? 若不行,還有其他選擇嗎? 非常感謝!
急 ~ ~ ~
請問如果今天我有兩群,其中ㄧ群有17 sample,另一群有400多 sample,那我用one ANOVA去找他們之間的差異,這樣的結果會因為兩群之間樣本數差異過大而導致不準確嗎?
你要用無母數Mann-Whitney解決兩樣本人數差距過大的問題
作者已經移除這則留言。
可否請教大大,如果資料中有類別資料又有連續性資料,我該用什麼統計分析方法比較好?QQ
@Sky,
結果變項是什麼?預測變項是什麼?要知道這兩種的類型,才能知道用什麼方法