什麼是層次迴歸 Hierarchical Regression?
當你搜尋「層次迴歸」時,維基百科說 Hierarchical linear modeling,Stata 說 Swamy-Arora estimator,統計書又說 hierarchical regression 是一種變數分批進入的方法。這些名詞到底有什麼關係?為什麼會搞混?
簡單來說:這其實是兩種完全不同的東西,只是中文都用了「層次」這個詞。
—
層次迴歸 = 變數分批進入模型
想像你是一位教育研究者,想預測學生的學業表現。你手上有兩類變數:
控制變數 :學生的家庭收入、父母教育程度、性別研究變數 :學生的學習動機
你不希望學習動機的「功勞」被控制變數稀釋,或者想先看控制變數能解釋多少變異,再加入研究變數看看能增加多少解釋力。
這時候你用的是 hierarchical regression ——把變數分「階」放入模型,一次一批:
第一階模型:成績 ~ 家庭收入 + 父母教育 + 性別
第二階模型:成績 ~ 家庭收入 + 父母教育 + 性別 + 學習動機
比較:ΔR² 就是學習動機的獨立貢獻這裡的「層次」指的是變數進入的順序層次 ,不是資料的結構層次。
用 SPSS 操作時,你會在「Block」欄位分批放入變數,就是這個概念。
—
HLM = 資料本身有巢套結構
現在換個場景:你想研究學校資源對學生成績的影響。你的資料長這樣:
50 所學校,每所學校 30 位學生
學生(Level 1)巢套在學校(Level 2)之內
這時候問題來了:
同一所學校的學生成績會比較接近(共同的老師、校風、設備)
這違反了一般迴歸「殘差獨立」的假設
如果你跑一般迴歸,標準誤會被低估,容易假性顯著
這時候你需要 Hierarchical Linear Modeling (HLM) ,多層次線性模式。
HLM 的「層次」指的是資料的階層結構 :
Level 1: 學生 i 在學校 j 的成績
Level 2: 學校 j 的平均資源水平
學生成績_ij = γ₀₀ + γ₀₁(學校資源_j) + u₀_j + ε_ij這裡處理的是資料依賴性 ,不是變數順序。
—
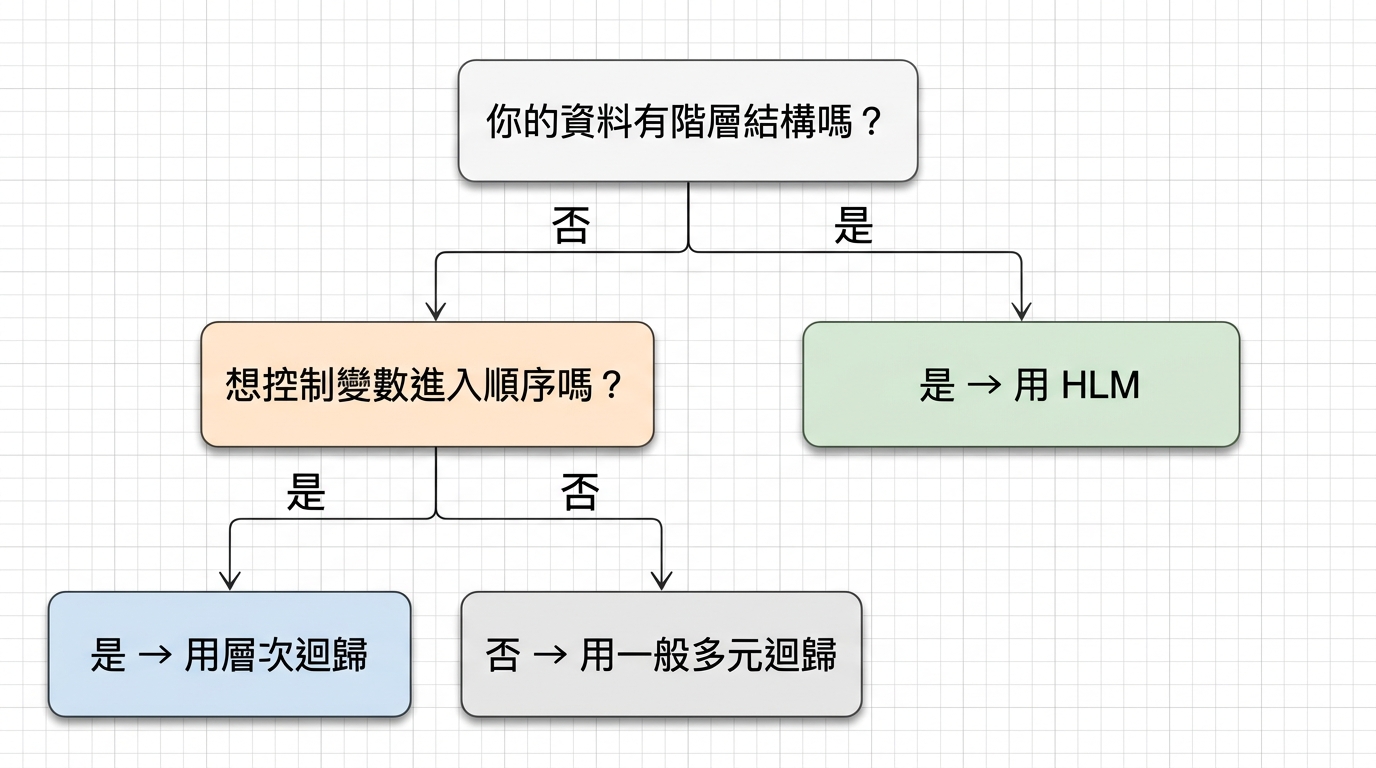
一張圖看懂如何選擇
這張圖總結了選擇邏輯:
問題 使用方法 想控制變數進入順序,看 incremental R²? 層次迴歸 資料有巢套結構(學生→班級→學校)? HLM 只是單純預測,沒有階層也沒有分批需求? 一般多元迴歸
—
常見誤區
「層次迴歸就是多層次模式」
– 錯。前者是變數管理策略,後者是處理資料依賴的統計方法。
「跑 HLM 比較高級,所以我應該用 HLM」
– 錯。如果資料沒有巢套結構,跑 HLM 是多餘的,甚至有過度參數化的風險。
「分批放變數一定要用 SPSS 的 Block 功能」
– 不一定。你可以手動跑多個模型比較 ΔR²,只是 Block 功能幫你省時間。
—
站內相關文章
若想深入了解,可以參考以下文章:
[多層次線性分析方法—HLM軟體應用](/?p=52):HLM6/7 …